并发编程笔记
本博客根据黑马java并发编程教程学习而做的笔记,链接如下
一、基本概念
1、进程与线程
进程
- 程序由指令和数据组成,但这些指令要运行,数据要读写,就必须将指令加载至 CPU,数据加载至内存。在指令运行过程中还需要用到磁盘、网络等设备。进程就是用来加载指令、管理内存、管理 IO 的。
- 当一个程序被运行,从磁盘加载这个程序的代码至内存,这时就开启了一个进程。
- 进程就可以视为程序的一个实例。大部分程序可以同时运行多个实例进程(例如记事本、画图、浏览器 等),也有的程序只能启动一个实例进程(例如网易云音乐、360 安全卫士等)
线程
- 一个进程之内可以分为一到多个线程。
- 一个线程就是一个指令流,将指令流中的一条条指令以一定的顺序交给 CPU 执行 。
- Java 中,线程作为小调度单位,进程作为资源分配的小单位。 在 windows 中进程是不活动的,只是作 为线程的容器
二者对比
进程基本上相互独立的,而线程存在于进程内,是进程的一个子集 进程拥有共享的资源,如内存空间等,供其内部的线程共享
进程间通信较为复杂 同一台计算机的进程通信称为 IPC(Inter-process communication)
不同计算机之间的进程通信,需要通过网络,并遵守共同的协议,例如 HTTP
线程通信相对简单,因为它们共享进程内的内存,一个例子是多个线程可以访问同一个共享变量 线程更轻量,线程上下文切换成本一般上要比进程上下文切换低
进程和线程的切换
上下文切换
内核为每一个进程维持一个上下文。上下文就是内核重新启动一个被抢占的进程所需的状态。包括以下内容:
- 通用目的寄存器
- 浮点寄存器
- 程序计数器
- 用户栈
- 状态寄存器
- 内核栈
- 各种内核数据结构:比如描绘地址空间的页表,包含有关当前进程信息的进程表,以及包含进程已打开文件的信息的文件表
进程切换和线程切换的主要区别
最主要的一个区别在于进程切换涉及虚拟地址空间的切换而线程不会。因为每个进程都有自己的虚拟地址空间,而线程是共享所在进程的虚拟地址空间的,因此同一个进程中的线程进行线程切换时不涉及虚拟地址空间的转换
页表查找是一个很慢的过程,因此通常使用cache来缓存常用的地址映射,这样可以加速页表查找,这个cache就是快表TLB(translation Lookaside Buffer,用来加速页表查找)。由于每个进程都有自己的虚拟地址空间,那么显然每个进程都有自己的页表,那么当进程切换后页表也要进行切换,页表切换后TLB就失效了,cache失效导致命中率降低,那么虚拟地址转换为物理地址就会变慢,表现出来的就是程序运行会变慢,而线程切换则不会导致TLB失效,因为线程线程无需切换地址空间,因此我们通常说线程切换要比较进程切换快
而且还可能出现缺页中断,这就需要操作系统将需要的内容调入内存中,若内存已满则还需要将不用的内容调出内存,这也需要花费时间
为什么TLB能加快访问速度
快表可以避免每次都对页号进行地址的有效性判断。快表中保存了对应的物理块号,可以直接计算出物理地址,无需再进行有效性检查
2、并发与并行
并发是一个CPU在不同的时间去不同线程中执行指令。
并行是多个CPU同时处理不同的线程。
引用 Rob Pike 的一段描述:
- 并发(concurrent)是同一时间应对(dealing with)多件事情的能力
- 并行(parallel)是同一时间动手做(doing)多件事情的能力
3、应用
应用之异步调用(案例1)
以调用方角度来讲,如果
需要等待结果返回,才能继续运行就是同步
不需要等待结果返回,就能继续运行就是异步
1) 设计
多线程可以让方法执行变为异步的(即不要巴巴干等着)比如说读取磁盘文件时,假设读取操作花费了 5 秒钟,如 果没有线程调度机制,这 5 秒 cpu 什么都做不了,其它代码都得暂停…
2) 结论
比如在项目中,视频文件需要转换格式等操作比较费时,这时开一个新线程处理视频转换,避免阻塞主线程
tomcat 的异步 servlet 也是类似的目的,让用户线程处理耗时较长的操作,避免阻塞
tomcat 的工作线程 ui 程序中,开线程进行其他操作,避免阻塞 ui 线程
结论
单核 cpu 下,多线程不能实际提高程序运行效率,只是为了能够在不同的任务之间切换,不同线程轮流使用 cpu ,不至于一个线程总占用 cpu,别的线程没法干活
多核 cpu 可以并行跑多个线程,但能否提高程序运行效率还是要分情况的
有些任务,经过精心设计,将任务拆分,并行执行,当然可以提高程序的运行效率。但不是所有计算任 务都能拆分(参考后文的【阿姆达尔定律】)
也不是所有任务都需要拆分,任务的目的如果不同,谈拆分和效率没啥意义
IO 操作不占用 cpu,只是我们一般拷贝文件使用的是【阻塞 IO】,这时相当于线程虽然不用 cpu,但需要一 直等待 IO 结束,没能充分利用线程。所以才有后面的【非阻塞 IO】和【异步 IO】优化
二、线程的创建
1、创建一个线程(非主线程)
方法一:通过继承Thread创建线程
public class CreateThread {
public static void main(String[] args) {
Thread myThread = new MyThread();
// 启动线程
myThread.start();
}
}
class MyThread extends Thread {
@Override
public void run() {
System.out.println("my thread running...");
}
}使用继承方式的好处是,在run()方法内获取当前线程直接使用this就可以了,无须使用Thread.currentThread()方法;不好的地方是Java不支持多继承,如果继承了Thread类,那么就不能再继承其他类。另外任务与代码没有分离,当多个线程执行一样的任务时需要多份任务代码
方法二:使用Runnable配合Thread(推荐)
public class Test2 {
public static void main(String[] args) {
//创建线程任务
Runnable r = new Runnable() {
@Override
public void run() {
System.out.println("Runnable running");
}
};
//将Runnable对象传给Thread
Thread t = new Thread(r);
//启动线程
t.start();
}
}或者
public class CreateThread2 {
private static class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("my runnable running...");
}
}
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
}
}通过实现Runnable接口,并且实现run()方法。在创建线程时作为参数传入该类的实例即可
方法二的简化:使用lambda表达式简化操作
当一个接口带有@FunctionalInterface注解时,是可以使用lambda来简化操作的
所以方法二中的代码可以被简化为
public class Test2 {
public static void main(String[] args) {
//创建线程任务
Runnable r = () -> {
//直接写方法体即可
System.out.println("Runnable running");
System.out.println("Hello Thread");
};
//将Runnable对象传给Thread
Thread t = new Thread(r);
//启动线程
t.start();
}
}可以再Runnable上使用Alt+Enter

原理之 Thread 与 Runnable 的关系
分析 Thread 的源码,理清它与 Runnable 的关系
小结
- 方法1 是把线程和任务合并在了一起
- 方法2 是把线程和任务分开了
- 用 Runnable 更容易与线程池等高级 API 配合 用 Runnable 让任务类脱离了 Thread 继承体系,更灵活
方法三:使用FutureTask与Thread结合
使用FutureTask可以用泛型指定线程的返回值类型(Runnable的run方法没有返回值)
public class Test3 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//需要传入一个Callable对象
FutureTask<Integer> task = new FutureTask<Integer>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
System.out.println("线程执行!");
Thread.sleep(1000);
return 100;
}
});
Thread r1 = new Thread(task, "t2");
r1.start();
//获取线程中方法执行后的返回结果
System.out.println(task.get());
}
}或
public class UseFutureTask {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> futureTask = new FutureTask<>(new MyCall());
Thread thread = new Thread(futureTask);
thread.start();
// 获得线程运行后的返回值
System.out.println(futureTask.get());
}
}
class MyCall implements Callable<String> {
@Override
public String call() throws Exception {
return "hello world";
}
}总结
使用继承方式的好处是方便传参,你可以在子类里面添加成员变量,通过set方法设置参数或者通过构造函数进行传递,而如果使用Runnable方式,则只能使用主线程里面被声明为final的变量。不好的地方是Java不支持多继承,如果继承了Thread类,那么子类不能再继承其他类,而Runable则没有这个限制。前两种方式都没办法拿到任务的返回结果,但是Futuretask方式可以
2、原理之线程运行
栈与栈帧
Java Virtual Machine Stacks (Java 虚拟机栈) 我们都知道 JVM 中由堆、栈、方法区所组成,其中栈内存是给谁用的呢?
- 其实就是线程,每个线程启动后,虚拟机就会为其分配一块栈内存
- 每个栈由多个栈帧(Frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
线程上下文切换(Thread Context Switch)
因为以下一些原因导致 cpu 不再执行当前的线程,转而执行另一个线程的代码
- 线程的 cpu 时间片用完
- 垃圾回收 有更高优先级的线程需要运行
- 线程自己调用了 sleep、yield、wait、join、park、synchronized、lock 等方法
当 Context Switch 发生时,需要由操作系统保存当前线程的状态,并恢复另一个线程的状态,Java 中对应的概念 就是程序计数器(Program Counter Register),它的作用是记住下一条 jvm 指令的执行地址,是线程私有的
- 状态包括程序计数器、虚拟机栈中每个栈帧的信息,如局部变量、操作数栈、返回地址等
- Context Switch 频繁发生会影响性能
3、常用方法
(1)start() vs run()
被创建的Thread对象直接调用重写的run方法时, run方法是在主线程中被执行的,而不是在我们所创建的线程中执行。所以如果想要在所创建的线程中执行run方法,需要使用Thread对象的start方法。
(2)sleep()与yield()
sleep (使线程阻塞)
调用 sleep 会让当前线程从 Running 进入 Timed Waiting 状态(阻塞),可通过state()方法查看
其它线程可以使用 interrupt 方法打断正在睡眠的线程,这时 sleep 方法会抛出 InterruptedException
睡眠结束后的线程未必会立刻得到执行
建议用 TimeUnit 的 sleep 代替 Thread 的 sleep 来获得更好的可读性 。如:
//休眠一秒 TimeUnit.SECONDS.sleep(1); //休眠一分钟 TimeUnit.MINUTES.sleep(1);
yield (让出当前线程)
- 调用 yield 会让当前线程从 Running 进入 Runnable 就绪状态(仍然有可能被执行),然后调度执行其它线程
- 具体的实现依赖于操作系统的任务调度器
线程优先级
线程优先级会提示(hint)调度器优先调度该线程,但它仅仅是一个提示,调度器可以忽略它
如果 cpu 比较忙,那么优先级高的线程会获得更多的时间片,但 cpu 闲时,优先级几乎没作用
设置方法:
thread1.setPriority(Thread.MAX_PRIORITY); //设置为优先级最高
(3)join()方法
用于等待某个线程结束。哪个线程内调用join()方法,就等待哪个线程结束,然后再去执行其他线程。
如在主线程中调用ti.join(),则是主线程等待t1线程结束
Thread thread = new Thread();
//等待thread线程执行结束
thread.join();
//最多等待1000ms,如果1000ms内线程执行完毕,则会直接执行下面的语句,不会等够1000ms
thread.join(1000);(4)interrupt()方法
用于打断阻塞(sleep wait join…)的线程。 处于阻塞状态的线程,CPU不会给其分配时间片。
- 如果一个线程在在运行中被打断,打断标记会被置为true。
- 如果是打断因sleep wait join方法而被阻塞的线程,会将打断标记置为false
//用于查看打断标记,返回值被boolean类型
t1.isInterrupted();正常运行的线程在被打断后,不会停止,会继续执行。如果要让线程在被打断后停下来,需要使用打断标记来判断。
while(true) {
if(Thread.currentThread().isInterrupted()) {
break;
}
}interrupt方法的应用——两阶段终止模式
当我们在执行线程一时,想要终止线程二,这是就需要使用interrupt方法来优雅的停止线程二。
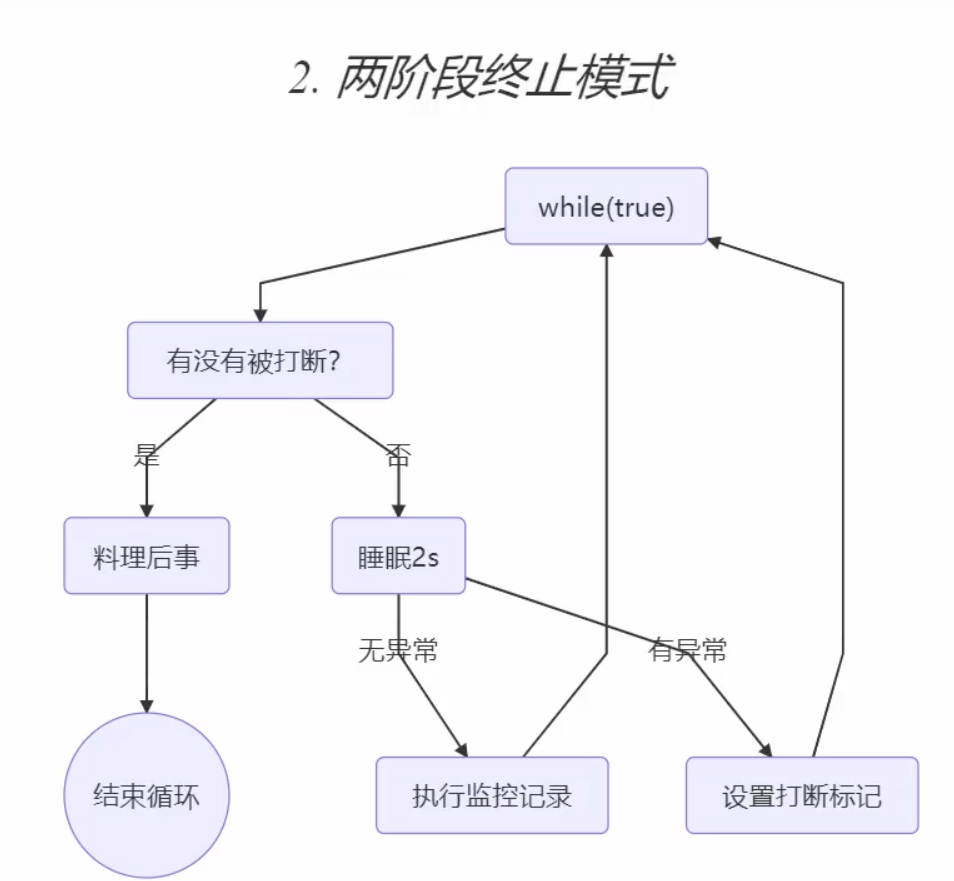
代码
public class Test7 {
public static void main(String[] args) throws InterruptedException {
Monitor monitor = new Monitor();
monitor.start();
Thread.sleep(3500);
monitor.stop();
}
}
class Monitor {
Thread monitor;
/**
* 启动监控器线程
*/
public void start() {
//设置线控器线程,用于监控线程状态
monitor = new Thread() {
@Override
public void run() {
//开始不停的监控
while (true) {
//判断当前线程是否被打断了
if(Thread.currentThread().isInterrupted()) {
System.out.println("处理后续任务");
//终止线程执行
break;
}
System.out.println("监控器运行中...");
try {
//线程休眠
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
//如果是在休眠的时候被打断,不会将打断标记设置为true,这时要重新设置打断标记
Thread.currentThread().interrupt();
}
}
}
};
monitor.start();
}
/**
* 用于停止监控器线程
*/
public void stop() {
//打断线程
monitor.interrupt();
}
}(5)不推荐使用的打断方法
- stop方法 停止线程运行(可能造成共享资源无法被释放,其他线程无法使用这些共享资源)
- suspend(暂停线程)/resume(恢复线程)方法
(6)守护线程
当JAVA进程中有多个线程在执行时,只有当所有非守护线程都执行完毕后,JAVA进程才会结束。但当非守护线程全部执行完毕后,守护线程无论是否执行完毕,也会一同结束。
//将线程设置为守护线程, 默认为false
monitor.setDaemon(true);守护线程的应用
- 垃圾回收器线程就是一种守护线程
- Tomcat 中的 Acceptor 和 Poller 线程都是守护线程,所以 Tomcat 接收到 shutdown 命令后,不会等 待它们处理完当前请求
4、线程的状态
(1)五种状态
这是从 操作系统 层面来描述的
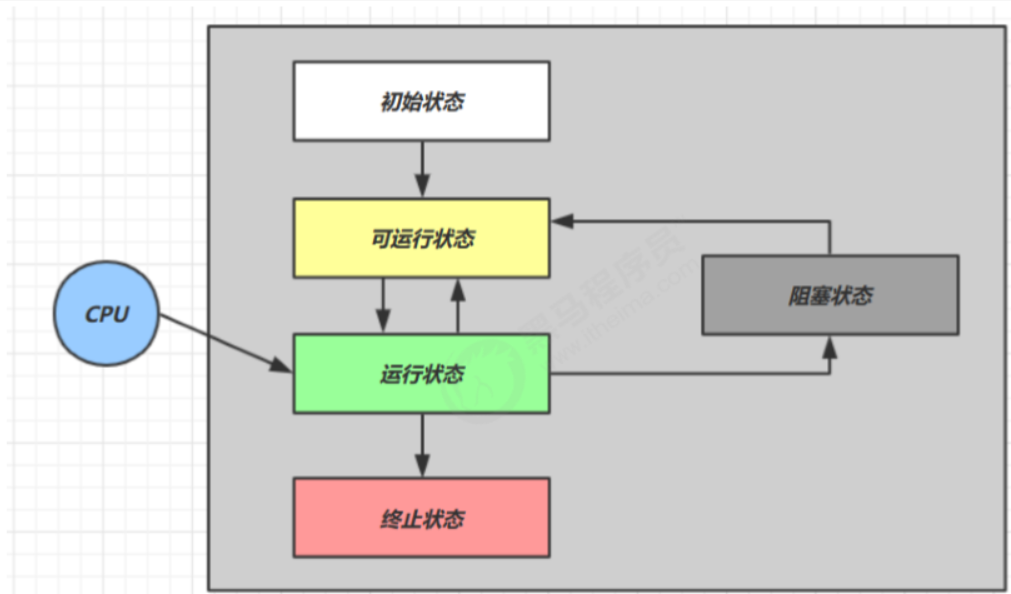
【初始状态】仅是在语言层面创建了线程对象,还未与操作系统线程关联(例如线程调用了start方法)
【可运行状态】(就绪状态)指该线程已经被创建(与操作系统线程关联),可以由 CPU 调度执行
【运行状态】指获取了 CPU 时间片运行中的状态
- 当 CPU 时间片用完,会从【运行状态】转换至【可运行状态】,会导致线程的上下文切换
【阻塞状态】
- 如果调用了阻塞 API,如 BIO 读写文件,这时该线程实际不会用到 CPU,会导致线程上下文切换,进入 【阻塞状态】
- 等 BIO 操作完毕,会由操作系统唤醒阻塞的线程,转换至【可运行状态】
- 与【可运行状态】的区别是,对【阻塞状态】的线程来说只要它们一直不唤醒,调度器就一直不会考虑调度它们
【终止状态】表示线程已经执行完毕,生命周期已经结束,不会再转换为其它状态
(2)六种状态
这是从 Java API 层面来描述的
根据 Thread.State 枚举,分为六种状态
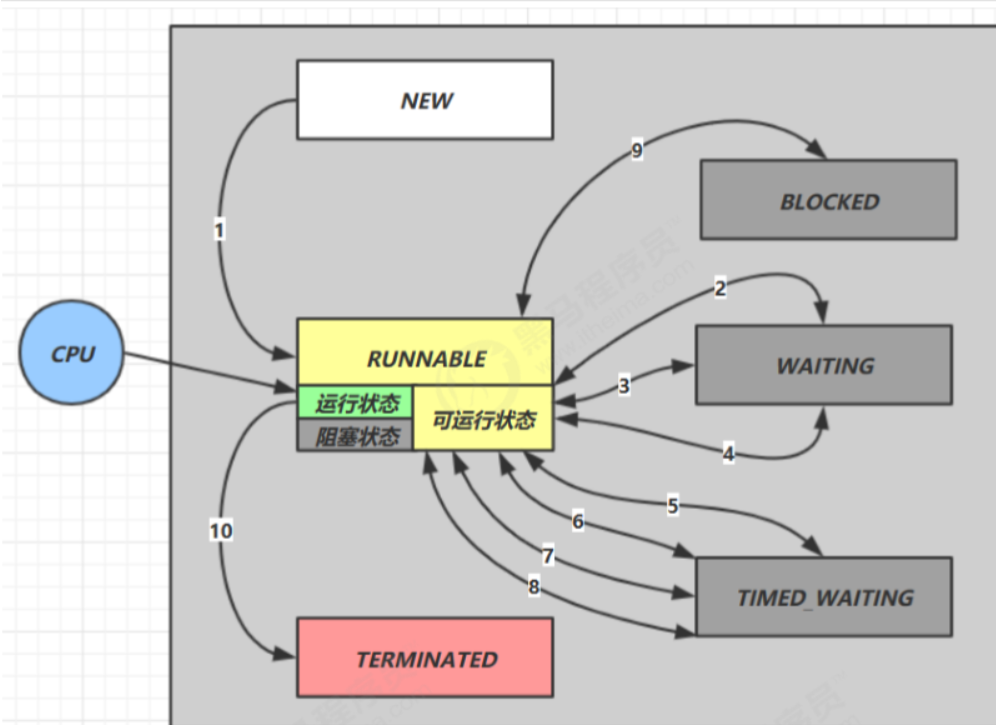
- NEW 线程刚被创建,但是还没有调用 start() 方法
- RUNNABLE 当调用了 start() 方法之后,注意,Java API 层面的 RUNNABLE 状态涵盖了操作系统层面的 【可运行状态】、【运行状态】和【阻塞状态】(由于 BIO 导致的线程阻塞,在 Java 里无法区分,仍然认为 是可运行)
- BLOCKED , WAITING , TIMED_WAITING 都是 Java API 层面对【阻塞状态】的细分,如sleep就位TIMED_WAITING, join为WAITING状态。后面会在状态转换一节详述。
- TERMINATED 当线程代码运行结束
三、共享模型之管程
1、共享带来的问题
(1)临界区 Critical Section
- 一个程序运行多个线程本身是没有问题的
- 问题出在多个线程访问共享资源
- 多个线程读共享资源其实也没有问题
- 在多个线程对共享资源读写操作时发生指令交错,就会出现问题
- 一段代码块内如果存在对共享资源的多线程读写操作,称这段代码块为临界区
例如,下面代码中的临界区
static int counter = 0;
static void increment()
// 临界区
{
counter++;
}
static void decrement()
// 临界区
{
counter--;
}(2)竞态条件 Race Condition
多个线程在临界区内执行,由于代码的执行序列不同而导致结果无法预测,称之为发生了竞态条件
2、synchronized 解决方案
(1)解决手段
为了避免临界区的竞态条件发生,有多种手段可以达到目的。
- 阻塞式的解决方案:synchronized,Lock
- 非阻塞式的解决方案:原子变量
本次课使用阻塞式的解决方案:synchronized,来解决上述问题,即俗称的【对象锁】,它采用互斥的方式让同一 时刻至多只有一个线程能持有【对象锁】,其它线程再想获取这个【对象锁】时就会阻塞住(blocked)。这样就能保证拥有锁 的线程可以安全的执行临界区内的代码,不用担心线程上下文切换
(2)synchronized语法
synchronized(对象) {
//临界区
}例:
static int counter = 0;
//创建一个公共对象,作为对象锁的对象
static final Object room = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
synchronized (room) {
counter++;
}
}
}, "t1");
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
synchronized (room) {
counter--;
}
}
}, "t2");
t1.start();
t2.start();
t1.join();
t2.join();
log.debug("{}",counter);
}(3)synchronized加在方法上
加在成员方法上
public class Demo { //在方法上加上synchronized关键字 public synchronized void test() { } //等价于 public void test() { synchronized(this) { } } }加在静态方法上
public class Demo { //在静态方法上加上synchronized关键字 public synchronized static void test() { } //等价于 public void test() { synchronized(Demo.class) { } } }
3、变量的线程安全分析
成员变量和静态变量是否线程安全?
如果它们没有共享,则线程安全
如果它们被共享了,根据它们的状态是否能够改变,又分两种情况
如果只有读操作,则线程安全
如果有读写操作,则这段代码是临界区,需要考虑线程安全
局部变量是否线程安全?
- 局部变量是线程安全的
- 但局部变量引用的对象则未必 (要看该对象是否被共享且被执行了读写操作)
- 如果该对象没有逃离方法的作用范围,它是线程安全的
- 如果该对象逃离方法的作用范围,需要考虑线程安全
- 局部变量是线程安全的——每个方法都在对应线程的栈中创建栈帧,不会被其他线程共享
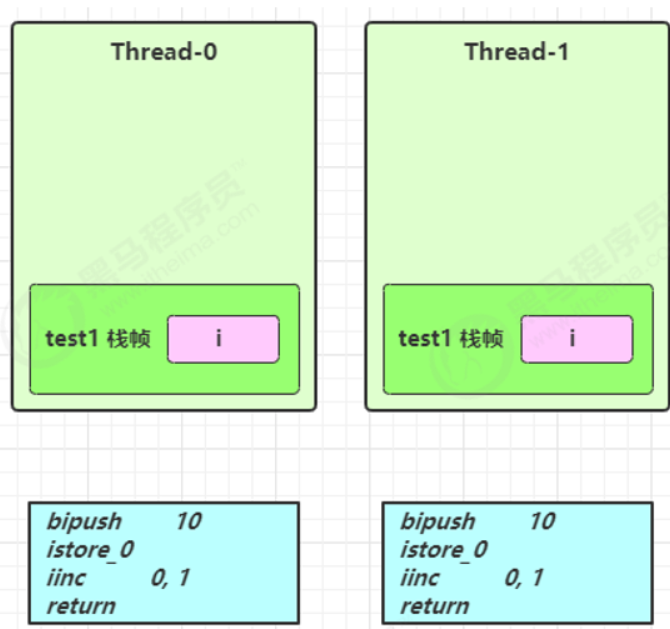
- 如果调用的对象被共享,且执行了读写操作,则线程不安全
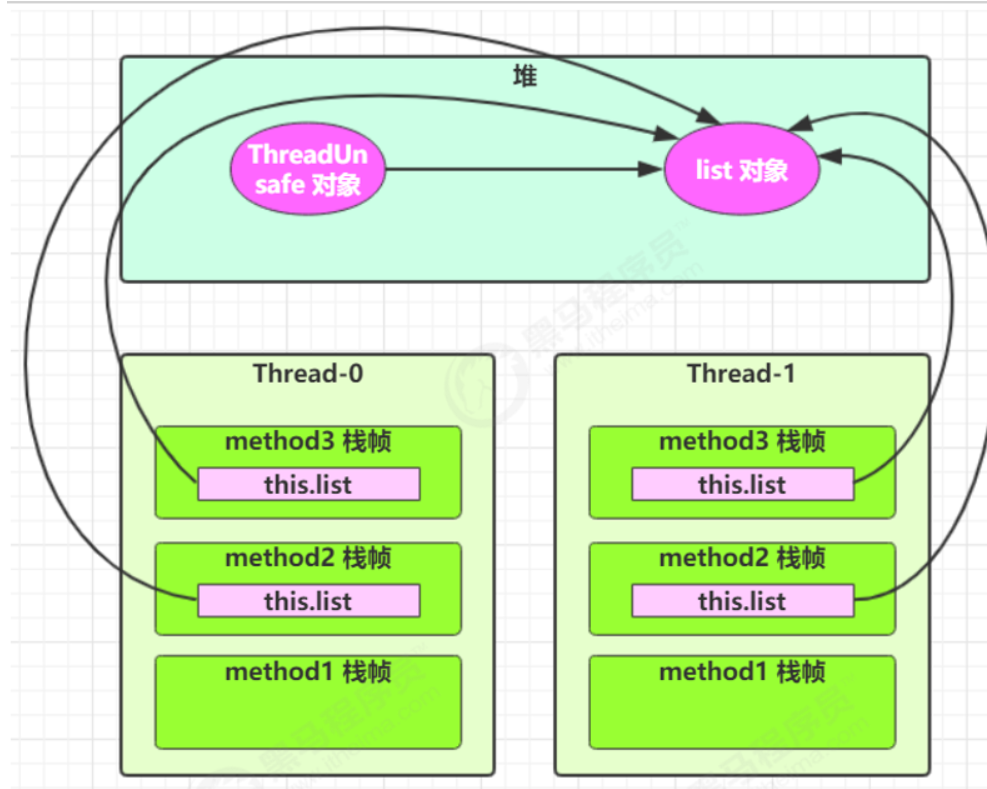
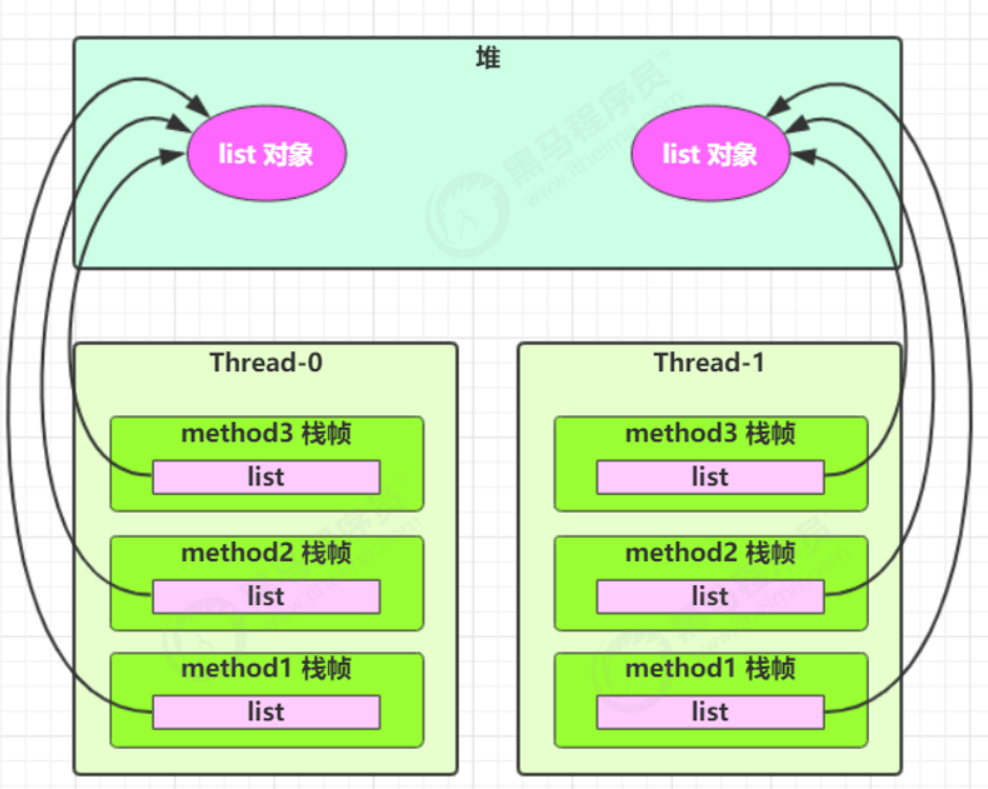
- 如果是局部变量,则会在堆中创建对应的对象,不会存在线程安全问题。
常见线程安全类
- String
- Integer
- StringBuffer
- Random
- Vector (List的线程安全实现类)
- Hashtable (Hash的线程安全实现类)
- java.util.concurrent 包下的类
这里说它们是线程安全的是指,多个线程调用它们同一个实例的某个方法时,是线程安全的
它们的每个方法是原子的(都被加上了synchronized)
但注意它们多个方法的组合不是原子的,所以可能会出现线程安全问题

不可变类线程安全性
String、Integer 等都是不可变类,因为其内部的状态不可以改变,因此它们的方法都是线程安全的
有同学或许有疑问,String 有 replace,substring 等方法【可以】改变值啊,那么这些方法又是如何保证线程安 全的呢?
这是因为这些方法的返回值都创建了一个新的对象,而不是直接改变String、Integer对象本身。
4、Monitor概念
(1)原理之Monitor
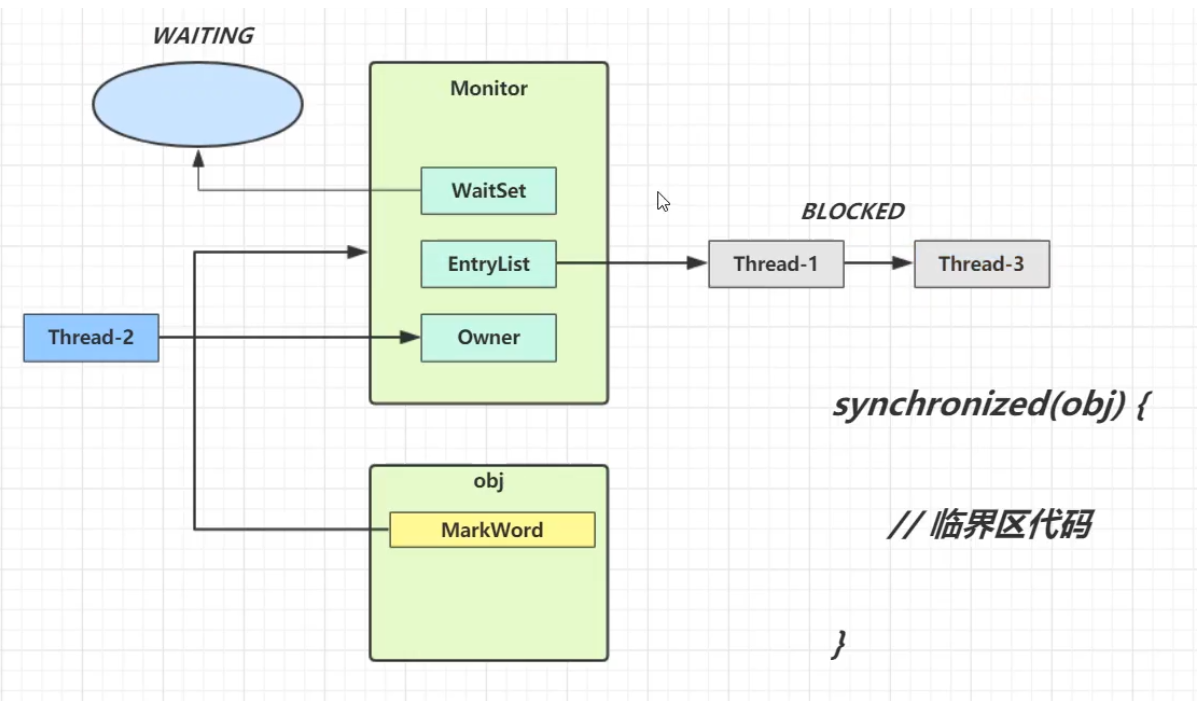
当线程执行到临界区代码时,如果使用了synchronized,会先查询synchronized中所指定的对象(obj)是否绑定了Monitor。
- 如果没有绑定,则会先去去与Monitor绑定,并且将Owner设为当前线程。
- 如果已经绑定,则会去查询该Monitor是否已经有了Owner
- 如果没有,则Owner与将当前线程绑定
- 如果有,则放入EntryList,进入阻塞状态(blocked)
当Monitor的Owner将临界区中代码执行完毕后,Owner便会被清空,此时EntryList中处于阻塞状态的线程会被叫醒并竞争,此时的竞争是非公平的
注意:
对象在使用了synchronized后与Monitor绑定时,会将对象头中的Mark Word置为Monitor指针。
每个对象都会绑定一个唯一的Monitor,如果synchronized中所指定的对象(obj)不同,则会绑定不同的Monitor
5、Synchronized原理进阶
对象头格式

(1)轻量级锁(用于优化Monitor这类的重量级锁)
轻量级锁使用场景:当一个对象被多个线程所访问,但访问的时间是错开的(不存在竞争),此时就可以使用轻量级锁来优化。
创建锁记录(Lock Record)对象,每个线程的栈帧都会包含一个锁记录对象,内部可以存储锁定对象的mark word(不再一开始就使用Monitor)
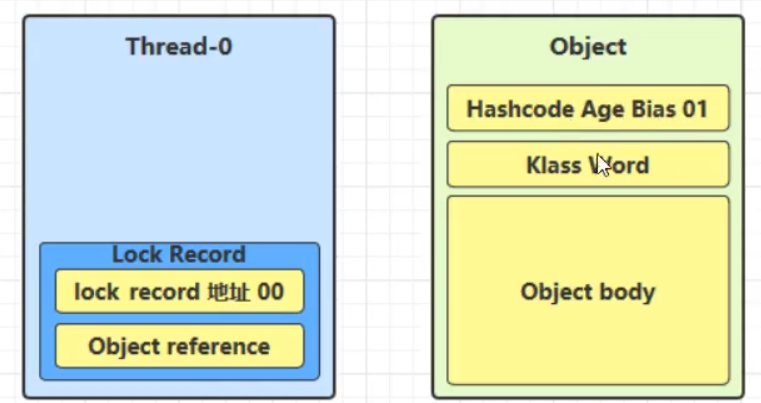
让锁记录中的Object reference指向锁对象(Object),并尝试用cas去替换Object中的mark word,将此mark word放入lock record中保存
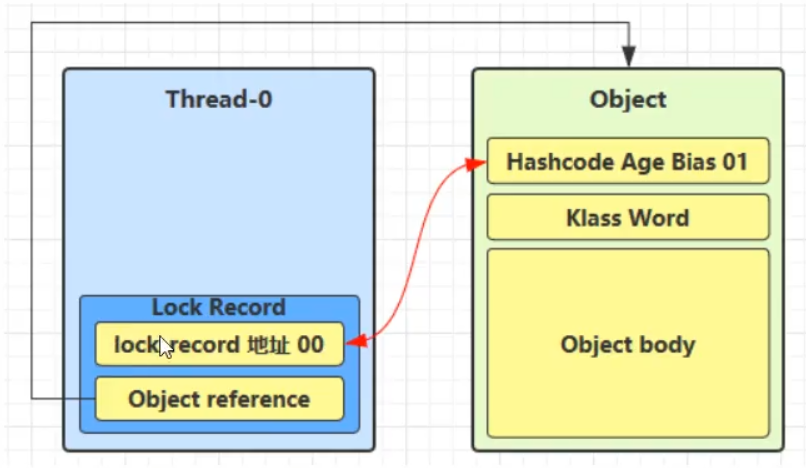
- 如果cas替换成功,则将Object的对象头替换为锁记录的地址和状态 00(轻量级锁状态),并由该线程给对象加锁
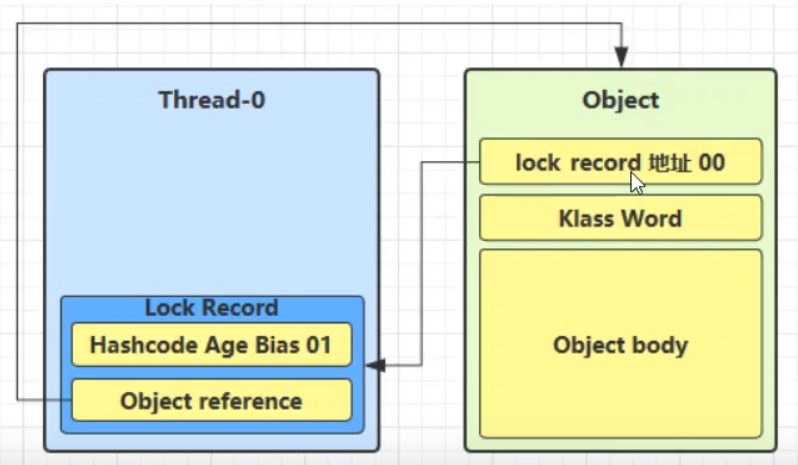
(2)锁膨胀
- 如果一个线程在给一个对象加轻量级锁时,cas替换操作失败(因为此时其他线程已经给对象加了轻量级锁),此时该线程就会进入锁膨胀过程
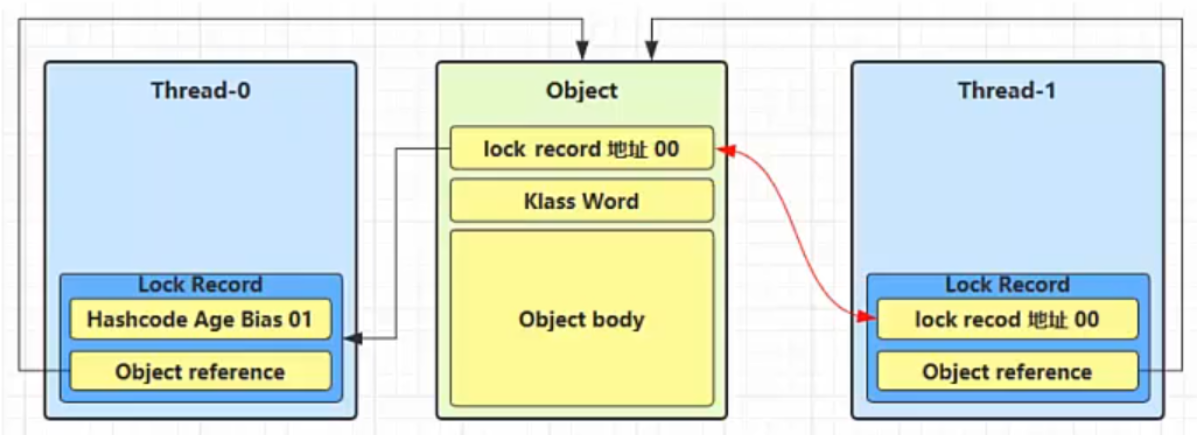
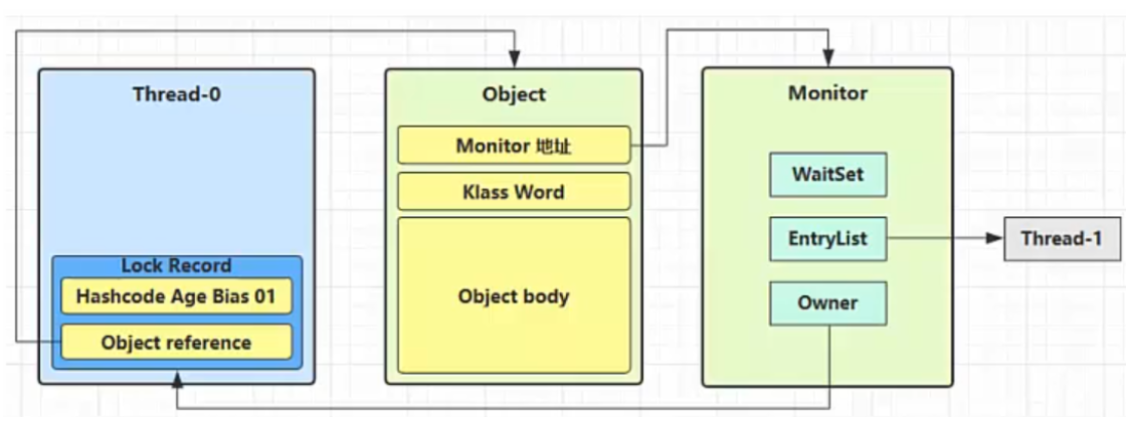
此时便会给对象加上重量级锁(使用Monitor)
将对象头的Mark Word改为Monitor的地址,并且状态改为01(重量级锁)
并且该线程放入入EntryList中,并进入阻塞状态(blocked)
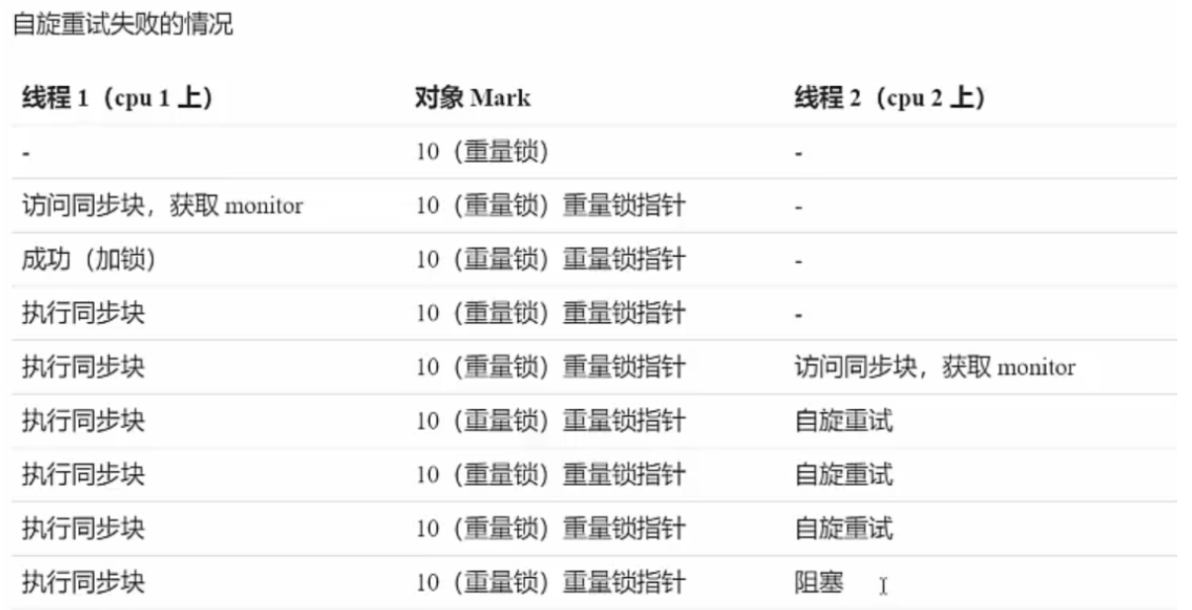
(3)自旋优化
重量级锁竞争时,还可以使用自选来优化,如果当前线程在自旋成功(使用锁的线程退出了同步块,释放了锁),这时就可以避免线程进入阻塞状态。
- 第一种情况
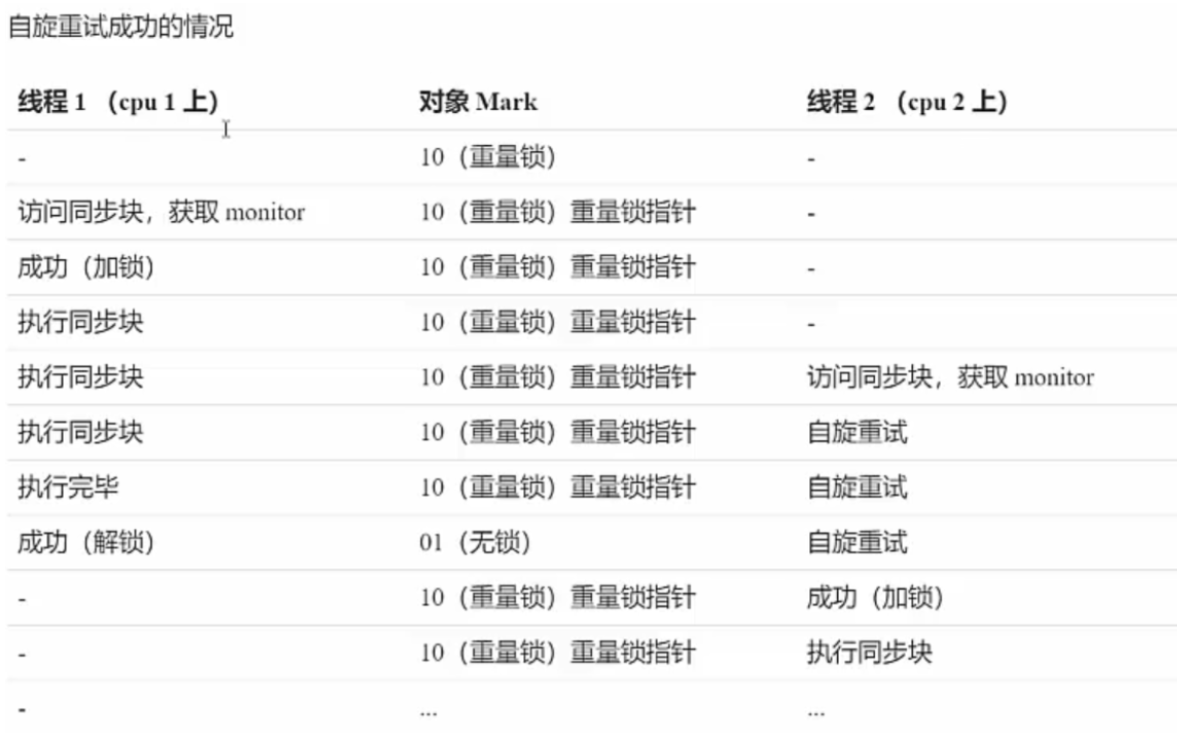
- 第二种情况
(4)偏向锁(用于优化轻量级锁重入)
轻量级锁在没有竞争时,每次重入(该线程执行的方法中再次锁住该对象)操作仍需要cas替换操作,这样是会使性能降低的。
所以引入了偏向锁对性能进行优化:在第一次cas时会将线程的ID写入对象的Mark Word中。此后发现这个线程ID就是自己的,就表示没有竞争,就不需要再次cas,以后只要不发生竞争,这个对象就归该线程所有。

偏向状态
- Normal:一般状态,没有加任何锁,前面62位保存的是对象的信息,最后2位为状态(01),倒数第三位表示是否使用偏向锁(未使用:0)
- Biased:偏向状态,使用偏向锁,前面54位保存的当前线程的ID,最后2位为状态(01),倒数第三位表示是否使用偏向锁(使用:1)
- Lightweight:使用轻量级锁,前62位保存的是锁记录的指针,最后两位为状态(00)
- Heavyweight:使用重量级锁,前62位保存的是Monitor的地址指针,后两位为状态(10)

- 如果开启了偏向锁(默认开启),在创建对象时,对象的Mark Word后三位应该是101
- 但是偏向锁默认是有延迟的,不会再程序一启动就生效,而是会在程序运行一段时间(几秒之后),才会对创建的对象设置为偏向状态
- 如果没有开启偏向锁,对象的Mark Word后三位应该是001
撤销偏向
以下几种情况会使对象的偏向锁失效
- 调用对象的hashCode方法
- 多个线程使用该对象
- 调用了wait/notify方法(调用wait方法会导致锁膨胀而使用重量级锁)
(5)批量重偏向
- 如果对象虽然被多个线程访问,但是线程间不存在竞争,这时偏向T1的对象仍有机会重新偏向T2
- 重偏向会重置Thread ID
- 当撤销超过20次后(超过阈值),JVM会觉得是不是偏向错了,这时会在给对象加锁时,重新偏向至加锁线程。
(6)批量撤销
当撤销偏向锁的阈值超过40以后,就会将整个类的对象都改为不可偏向的
6、Wait/Notify
(1)原理
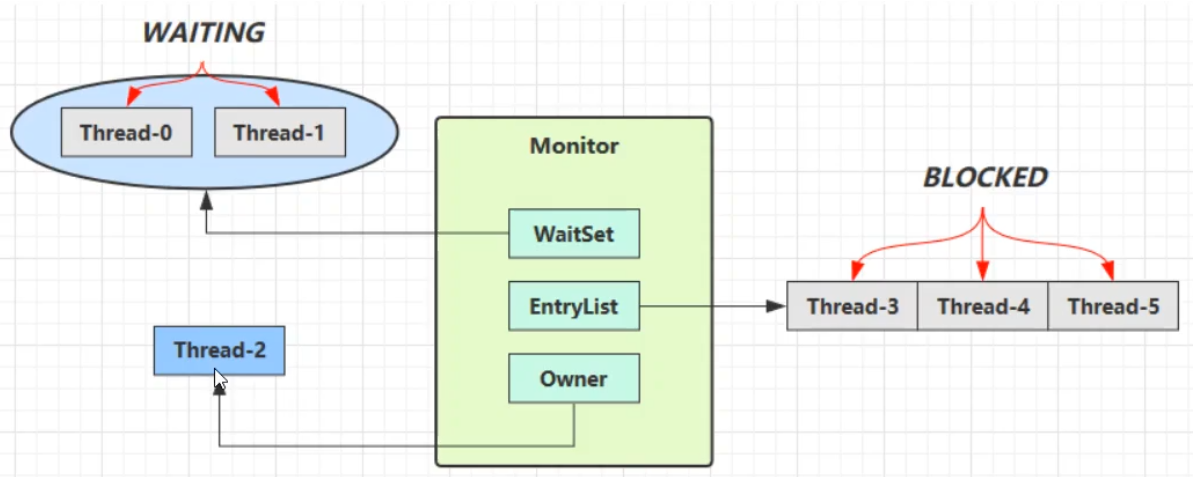
- 锁对象调用wait方法(obj.wait),就会使当前线程进入WaitSet中,变为WAITING状态。
- 处于BLOCKED和WAITING状态的线程都为阻塞状态,CPU都不会分给他们时间片。但是有所区别:
- BLOCKED状态的线程是在竞争对象时,发现Monitor的Owner已经是别的线程了,此时就会进入EntryList中,并处于BLOCKED状态
- WAITING状态的线程是获得了对象的锁,但是自身因为某些原因需要进入阻塞状态时,锁对象调用了wait方法而进入了WaitSet中,处于WAITING状态
- BLOCKED状态的线程会在锁被释放的时候被唤醒,但是处于WAITING状态的线程只有被锁对象调用了notify方法(obj.notify/obj.notifyAll),才会被唤醒。
注:只有当对象被锁以后,才能调用wait和notify方法
public class Test1 {
final static Object LOCK = new Object();
public static void main(String[] args) throws InterruptedException {
//只有在对象被锁住后才能调用wait方法
synchronized (LOCK) {
LOCK.wait();
}
}
}(2)Wait与Sleep的区别
不同点
- Sleep是Thread类的静态方法,Wait是Object的方法,Object又是所有类的父类,所以所有类都有Wait方法。
- Sleep在阻塞的时候不会释放锁,而Wait在阻塞的时候会释放锁
- Sleep不需要与synchronized一起使用,而Wait需要与synchronized一起使用(对象被锁以后才能使用)
相同点
- 阻塞状态都为TIMED_WAITING
(3)优雅地使用wait/notify
什么时候适合使用wait
- 当线程不满足某些条件,需要暂停运行时,可以使用wait。这样会将对象的锁释放,让其他线程能够继续运行。如果此时使用sleep,会导致所有线程都进入阻塞,导致所有线程都没法运行,直到当前线程sleep结束后,运行完毕,才能得到执行。
使用wait/notify需要注意什么
- 当有多个线程在运行时,对象调用了wait方法,此时这些线程都会进入WaitSet中等待。如果这时使用了notify方法,可能会造成虚假唤醒(唤醒的不是满足条件的等待线程),这时就需要使用notifyAll方法
synchronized (LOCK) {
while(//不满足条件,一直等待,避免虚假唤醒) {
LOCK.wait();
}
//满足条件后再运行
}
synchronized (LOCK) {
//唤醒所有等待线程
LOCK.notifyAll();
}7、模式之保护性暂停
(1)定义
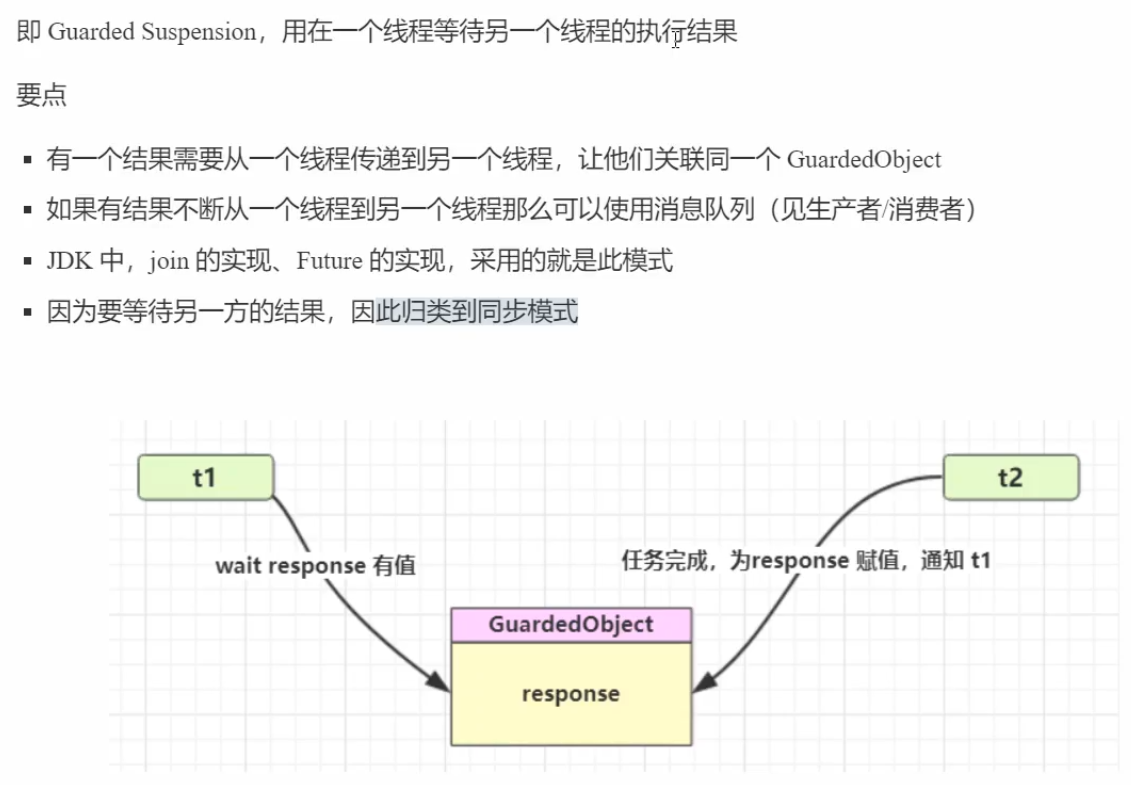
(2)举例
public class Test2 {
public static void main(String[] args) {
String hello = "hello thread!";
Guarded guarded = new Guarded();
new Thread(()->{
System.out.println("想要得到结果");
synchronized (guarded) {
System.out.println("结果是:"+guarded.getResponse());
}
System.out.println("得到结果");
}).start();
new Thread(()->{
System.out.println("设置结果");
synchronized (guarded) {
guarded.setResponse(hello);
}
}).start();
}
}
class Guarded {
/**
* 要返回的结果
*/
private Object response;
//优雅地使用wait/notify
public Object getResponse() {
//如果返回结果为空就一直等待,避免虚假唤醒
while(response == null) {
synchronized (this) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
return response;
}
public void setResponse(Object response) {
this.response = response;
synchronized (this) {
//唤醒休眠的线程
this.notifyAll();
}
}
@Override
public String toString() {
return "Guarded{" +
"response=" + response +
'}';
}
}带超时判断的暂停
public Object getResponse(long time) {
synchronized (this) {
//获取开始时间
long currentTime = System.currentTimeMillis();
//用于保存已经等待了的时间
long passedTime = 0;
while(response == null) {
//看经过的时间-开始时间是否超过了指定时间
long waitTime = time -passedTime;
if(waitTime <= 0) {
break;
}
try {
//等待剩余时间
this.wait(waitTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
//获取当前时间
passedTime = System.currentTimeMillis()-currentTime
}
}
return response;
}(3)join源码——使用保护性暂停模式
public final synchronized void join(long millis)
throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}8、park/unpark
(1)基本使用
park/unpark都是LockSupport类中的的方法
//暂停线程运行
LockSupport.park;
//恢复线程运行
LockSupport.unpark(thread);public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(()-> {
System.out.println("park");
//暂停线程运行
LockSupport.park();
System.out.println("resume");
}, "t1");
thread.start();
Thread.sleep(1000);
System.out.println("unpark");
//恢复线程运行
LockSupport.unpark(thread);
}(2)特点
与wait/notify的区别
- wait,notify 和 notifyAll 必须配合Object Monitor一起使用,而park,unpark不必
- park ,unpark 是以线程为单位来阻塞和唤醒线程,而 notify 只能随机唤醒一个等待线程,notifyAll 是唤醒所有等待线程,就不那么精确
- park & unpark 可以先 unpark,而 wait & notify 不能先 notify
- park不会释放锁,而wait会释放锁
(3)原理
每个线程都有一个自己的Park对象,并且该对象_counter, _cond,__mutex组成
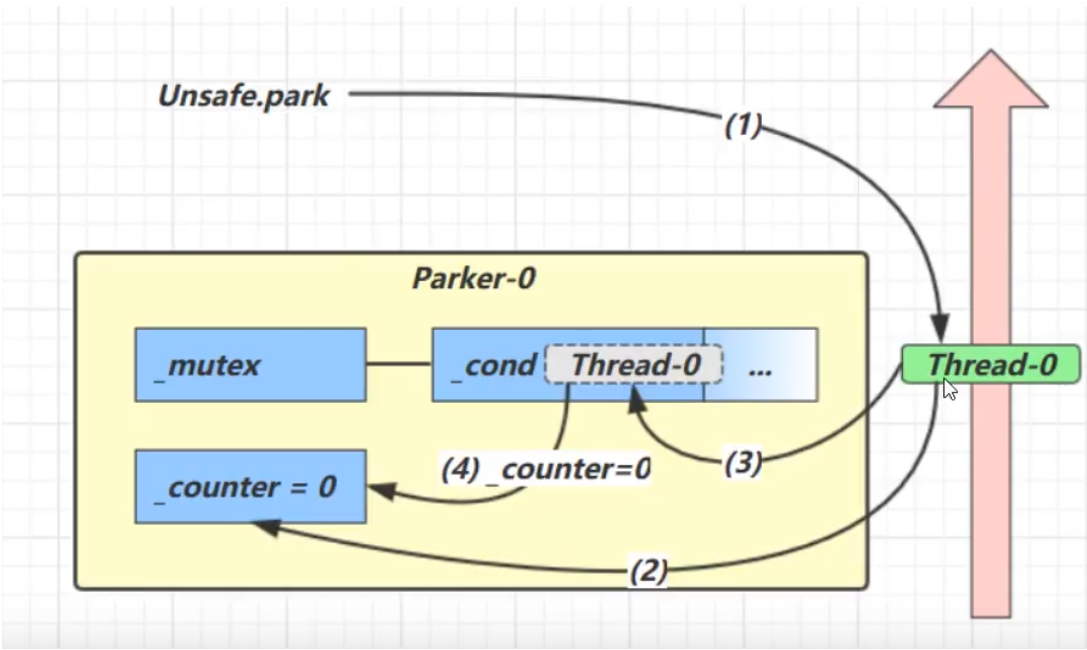
先调用park再调用unpark时
先调用park
- 线程运行时,会将Park对象中的_counter的值设为0;
- 调用park时,会先查看counter的值是否为0,如果为0,则将线程放入阻塞队列cond中
- 放入阻塞队列中后,会再次将counter设置为0
然后调用unpark
调用unpark方法后,会将counter的值设置为1
去唤醒阻塞队列cond中的线程
线程继续运行并将counter的值设为0
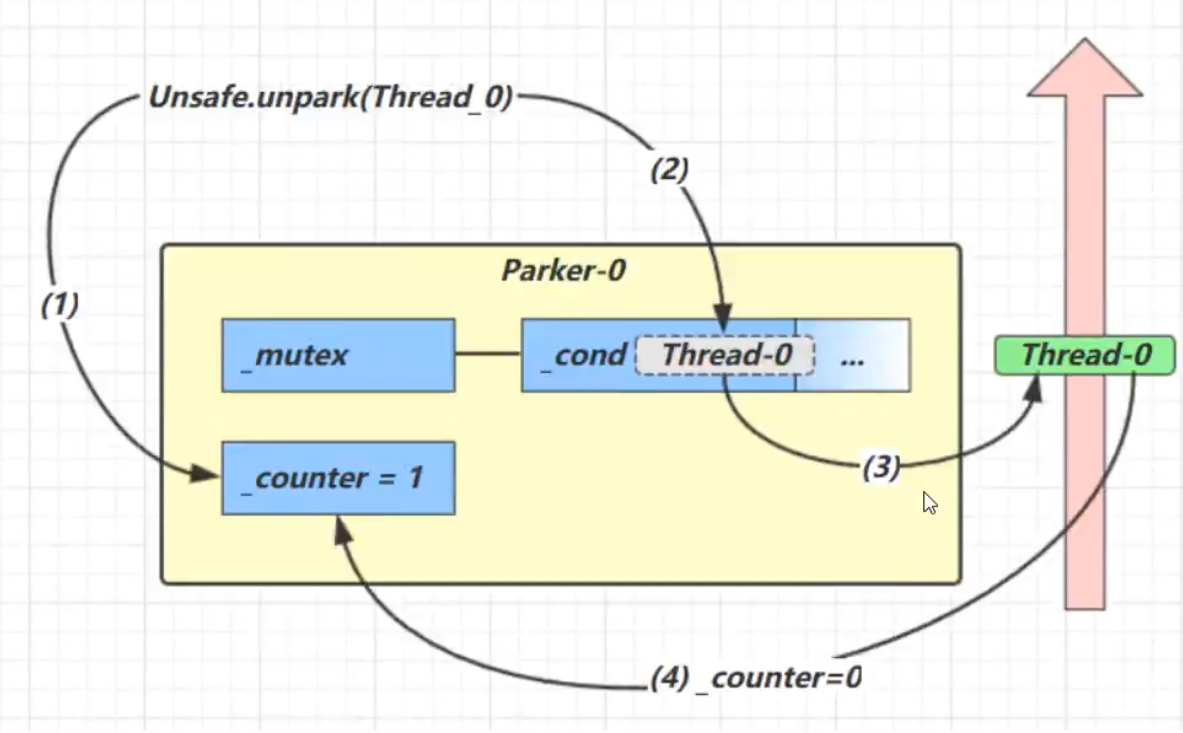
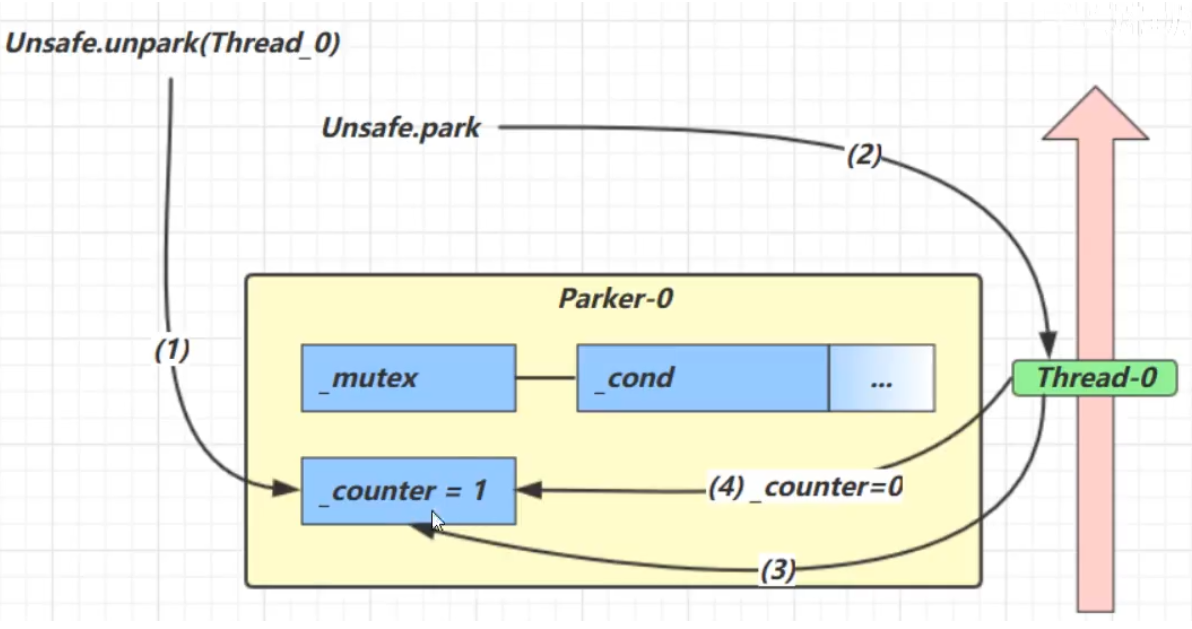
- 先调用unpark,再调用park
- 调用unpark
- 会将counter设置为1(运行时0)
- 调用park方法
- 查看counter是否为0
- 因为unpark已经把counter设置为1,所以此时将counter设置为0,但不放入阻塞队列cond中
- 调用unpark
9、线程中的状态转换
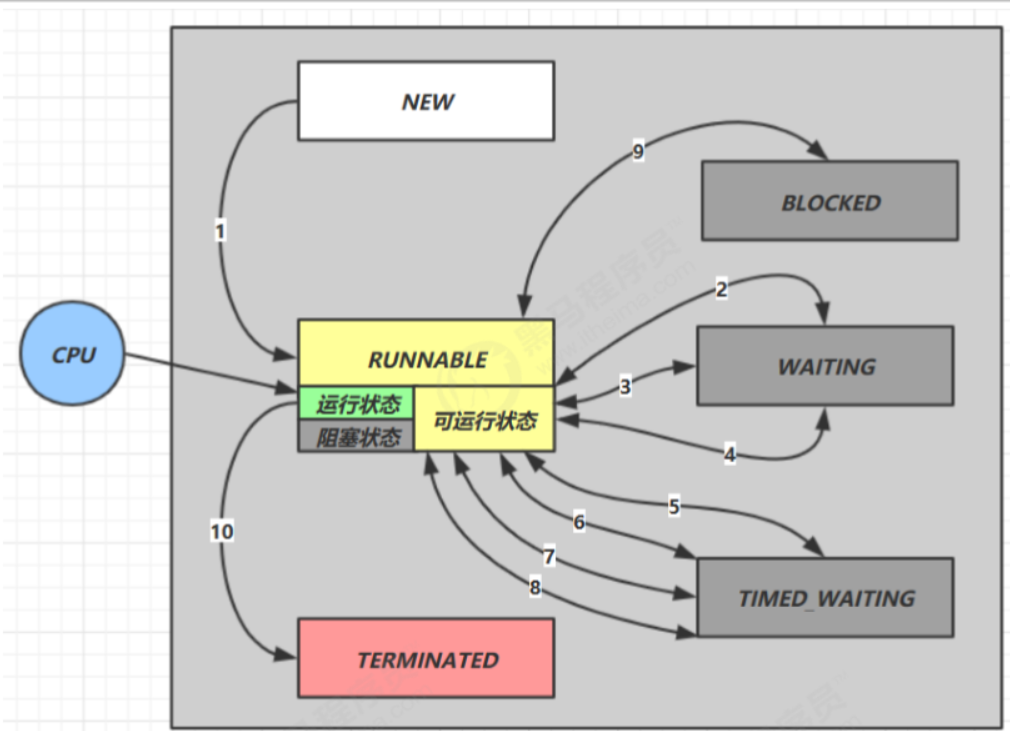
情况一:NEW –> RUNNABLE
- 当调用了t.start()方法时,由 NEW –> RUNNABLE
情况二: RUNNABLE <–> WAITING
- 当调用了t 线程用 synchronized(obj) 获取了对象锁后
- 调用 obj.wait() 方法时,t 线程从 RUNNABLE –> WAITING
- 调用 obj.notify() , obj.notifyAll() , t.interrupt() 时
- 竞争锁成功,t 线程从 WAITING –> RUNNABLE
- 竞争锁失败,t 线程从 WAITING –> BLOCKED
情况三:RUNNABLE <–> WAITING
- 当前线程调用 t.join() 方法时,当前线程从 RUNNABLE –> WAITING
- 注意是当前线程在t 线程对象的监视器上等待
- t 线程运行结束,或调用了当前线程的 interrupt() 时,当前线程从 WAITING –> RUNNABLE
情况四: RUNNABLE <–> WAITING
- 当前线程调用 LockSupport.park() 方法会让当前线程从 RUNNABLE –> WAITING
- 调用 LockSupport.unpark(目标线程) 或调用了线程 的 interrupt() ,会让目标线程从 WAITING –> RUNNABLE
情况五: RUNNABLE <–> TIMED_WAITING
t 线程用 synchronized(obj) 获取了对象锁后
- 调用 obj.wait(long n) 方法时,t 线程从 RUNNABLE –> TIMED_WAITING
- t 线程等待时间超过了 n 毫秒,或调用 obj.notify() , obj.notifyAll() , t.interrupt() 时
- 竞争锁成功,t 线程从 TIMED_WAITING –> RUNNABLE
- 竞争锁失败,t 线程从 TIMED_WAITING –> BLOCKED
情况六:RUNNABLE <–> TIMED_WAITING
- 当前线程调用 t.join(long n) 方法时,当前线程从 RUNNABLE –> TIMED_WAITING
- 注意是当前线程在t 线程对象的监视器上等待
- 当前线程等待时间超过了 n 毫秒,或t 线程运行结束,或调用了当前线程的 interrupt() 时,当前线程从 TIMED_WAITING –> RUNNABLE
情况七:RUNNABLE <–> TIMED_WAITING
- 当前线程调用 Thread.sleep(long n) ,当前线程从 RUNNABLE –> TIMED_WAITING
- 当前线程等待时间超过了 n 毫秒,当前线程从 TIMED_WAITING –> RUNNABLE
情况八:RUNNABLE <–> TIMED_WAITING
- 当前线程调用 LockSupport.parkNanos(long nanos) 或 LockSupport.parkUntil(long millis) 时,当前线 程从 RUNNABLE –> TIMED_WAITING
- 调用 LockSupport.unpark(目标线程) 或调用了线程 的 interrupt() ,或是等待超时,会让目标线程从 TIMED_WAITING–> RUNNABLE
情况九:RUNNABLE <–> BLOCKED
- t 线程用 synchronized(obj) 获取了对象锁时如果竞争失败,从 RUNNABLE –> BLOCKED
- 持 obj 锁线程的同步代码块执行完毕,会唤醒该对象上所有 BLOCKED 的线程重新竞争,如果其中 t 线程竞争 成功,从 BLOCKED –> RUNNABLE ,其它失败的线程仍然 BLOCKED
情况十: RUNNABLE <–> TERMINATED
当前线程所有代码运行完毕,进入 TERMINATED
10、多把锁
将锁的粒度细分
class BigRoom {
//额外创建对象来作为锁
private final Object studyRoom = new Object();
private final Object bedRoom = new Object();
}11、活跃性
(1)定义
因为某种原因,使得代码一直无法执行完毕,这样的现象叫做活跃性
(2)死锁
有这样的情况:一个线程需要同时获取多把锁,这时就容易发生死锁
如:t1线程获得A对象 锁,接下来想获取B对象的锁t2线程获得B对象锁,接下来想获取A对象的锁
public static void main(String[] args) {
final Object A = new Object();
final Object B = new Object();
new Thread(()->{
synchronized (A) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (B) {
}
}
}).start();
new Thread(()->{
synchronized (B) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (A) {
}
}
}).start();
}发生死锁的必要条件
- 互斥条件
- 在一段时间内,一种资源只能被一个进程所使用
- 请求和保持条件
- 进程已经拥有了至少一种资源,同时又去申请其他资源。因为其他资源被别的进程所使用,该进程进入阻塞状态,并且不释放自己已有的资源
- 不可抢占条件
- 进程对已获得的资源在未使用完成前不能被强占,只能在进程使用完后自己释放
- 循环等待条件
- 发生死锁时,必然存在一个进程——资源的循环链。
定位死锁的方法
jps+jstack ThreadID
在JAVA控制台中的Terminal中输入jps指令可以查看运行中的线程ID,使用jstack ThreadID可以查看线程状态。
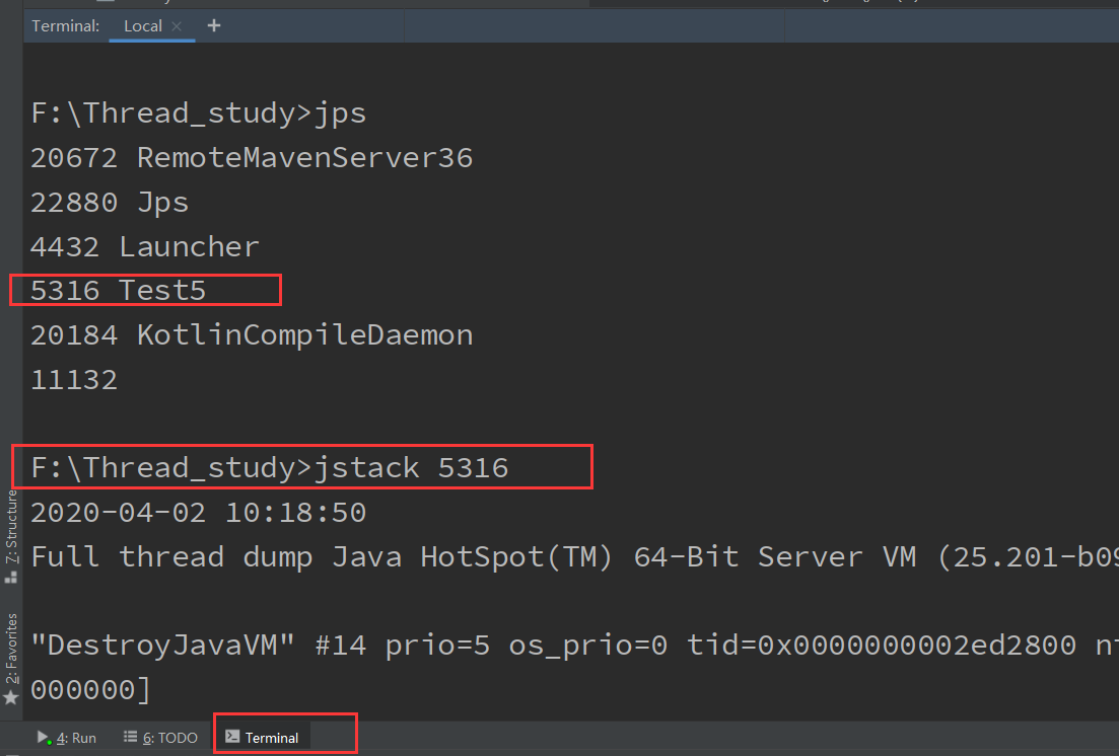
F:\Thread_study>jps 20672 RemoteMavenServer36 22880 Jps 4432 Launcher 5316 Test5 20184 KotlinCompileDaemon 11132 F:\Thread_study>jstack 5316
打印的结果
//找到一个java级别的死锁 Found one Java-level deadlock: ============================= "Thread-1": waiting to lock monitor 0x0000000017f40de8 (object 0x00000000d6188880, a java.lang.Object), which is held by "Thread-0" "Thread-0": waiting to lock monitor 0x0000000017f43678 (object 0x00000000d6188890, a java.lang.Object), which is held by "Thread-1"
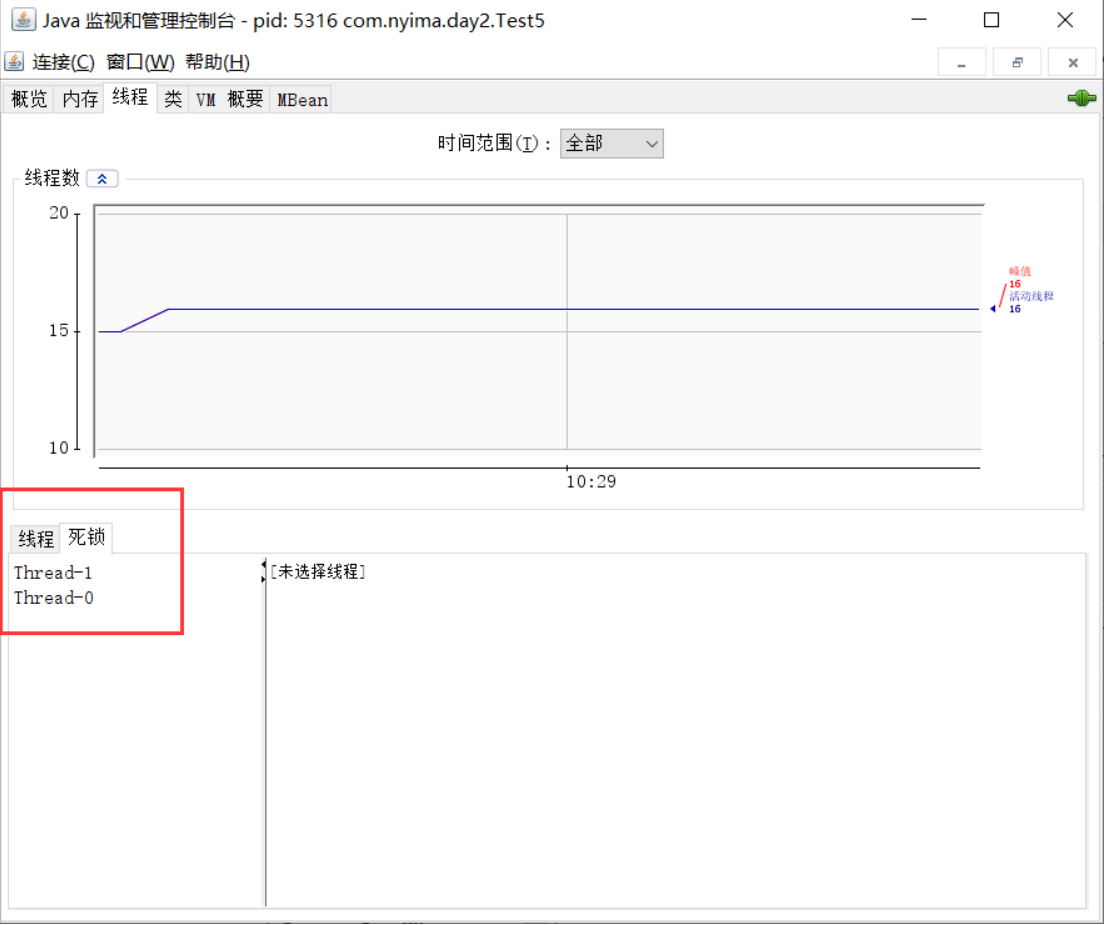
jconsole检测死锁

哲学家就餐问题
避免死锁的方法
在线程使用锁对象时,顺序加锁即可避免死锁
(3)活锁
活锁出现在两个线程互相改变对方的结束条件,后谁也无法结束。
避免活锁的方法
在线程执行时,中途给予不同的间隔时间即可。
死锁与活锁的区别
- 死锁是因为线程互相持有对象想要的锁,并且都不释放,最后到时线程阻塞,停止运行的现象。
- 活锁是因为线程间修改了对方的结束条件,而导致代码一直在运行,却一直运行不完的现象。
(4)饥饿
某些线程因为优先级太低,导致一直无法获得资源的现象。
在使用顺序加锁时,可能会出现饥饿现象
12、ReentrantLock
和synchronized相比具有的的特点
- 可中断
- 可以设置超时时间
- 可以设置为公平锁 (先到先得)
- 支持多个条件变量( 具有多个waitset)
基本语法
//获取ReentrantLock对象
private ReentrantLock lock = new ReentrantLock();
//加锁
lock.lock();
try {
//需要执行的代码
}finally {
//释放锁
lock.unlock();
}可重入
- 可重入是指同一个线程如果首次获得了这把锁,那么因为它是这把锁的拥有者,因此有权利再次获取这把锁
- 如果是不可重入锁,那么第二次获得锁时,自己也会被锁挡住
可打断
如果某个线程处于阻塞状态,可以调用其interrupt方法让其停止阻塞,获得锁失败
简而言之就是:处于阻塞状态的线程,被打断了就不用阻塞了,直接停止运行
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(()-> {
try {
//加锁,可打断锁
lock.lockInterruptibly();
} catch (InterruptedException e) {
e.printStackTrace();
//被打断,返回,不再向下执行
return;
}finally {
//释放锁
lock.unlock();
}
});
lock.lock();
try {
t1.start();
Thread.sleep(1000);
//打断
t1.interrupt();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}锁超时
使用lock.tryLock方法会返回获取锁是否成功。如果成功则返回true,反之则返回false。
并且tryLock方法可以指定等待时间,参数为:tryLock(long timeout, TimeUnit unit), 其中timeout为最长等待时间,TimeUnit为时间单位
简而言之就是:获取失败了、获取超时了或者被打断了,不再阻塞,直接停止运行
不设置等待时间
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(()-> {
//未设置等待时间,一旦获取失败,直接返回false
if(!lock.tryLock()) {
System.out.println("获取失败");
//获取失败,不再向下执行,返回
return;
}
System.out.println("得到了锁");
lock.unlock();
});
lock.lock();
try{
t1.start();
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}设置等待时间
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(()-> {
try {
//判断获取锁是否成功,最多等待1秒
if(!lock.tryLock(1, TimeUnit.SECONDS)) {
System.out.println("获取失败");
//获取失败,不再向下执行,直接返回
return;
}
} catch (InterruptedException e) {
e.printStackTrace();
//被打断,不再向下执行,直接返回
return;
}
System.out.println("得到了锁");
//释放锁
lock.unlock();
});
lock.lock();
try{
t1.start();
//打断等待
t1.interrupt();
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}公平锁
在线程获取锁失败,进入阻塞队列时,先进入的会在锁被释放后先获得锁。这样的获取方式就是公平的。
//默认是不公平锁,需要在创建时指定为公平锁
ReentrantLock lock = new ReentrantLock(true);条件变量
synchronized 中也有条件变量,就是我们讲原理时那个 waitSet 休息室,当条件不满足时进入waitSet 等待
ReentrantLock 的条件变量比 synchronized 强大之处在于,它是支持多个条件变量的,这就好比
- synchronized 是那些不满足条件的线程都在一间休息室等消息
- 而 ReentrantLock 支持多间休息室,有专门等烟的休息室、专门等早餐的休息室、唤醒时也是按休息室来唤 醒
使用要点:
- await 前需要获得锁
- await 执行后,会释放锁,进入 conditionObject 等待
- await 的线程被唤醒(或打断、或超时)取重新竞争 lock 锁
- 竞争 lock 锁成功后,从 await 后继续执
static Boolean judge = false;
public static void main(String[] args) throws InterruptedException {
ReentrantLock lock = new ReentrantLock();
//获得条件变量
Condition condition = lock.newCondition();
new Thread(()->{
lock.lock();
try{
while(!judge) {
System.out.println("不满足条件,等待...");
//等待
condition.await();
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("执行完毕!");
lock.unlock();
}
}).start();
new Thread(()->{
lock.lock();
try {
Thread.sleep(1);
judge = true;
//释放
condition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}).start();
}通过Lock与AQS实现可重入锁
public class MyLock implements Lock {
private static class Sync extends AbstractQueuedSynchronizer {
@Override
protected boolean tryAcquire(int arg) {
if (getExclusiveOwnerThread() == null) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
if (getExclusiveOwnerThread() == Thread.currentThread()) {
int state = getState();
compareAndSetState(state, state + 1);
return true;
}
return false;
}
@Override
protected boolean tryRelease(int arg) {
if (getState() <= 0) {
throw new IllegalMonitorStateException();
}
if (getExclusiveOwnerThread() != Thread.currentThread()) {
throw new IllegalMonitorStateException();
}
int state = getState();
if (state == 1) {
setExclusiveOwnerThread(null);
compareAndSetState(state, 0);
} else {
compareAndSetState(state, state - 1);
}
return true;
}
@Override
protected boolean isHeldExclusively() {
return getState() >= 1;
}
public Condition newCondition() {
return new ConditionObject();
}
}
Sync sync = new Sync();
@Override
public void lock() {
sync.acquire(1);
}
@Override
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
@Override
public boolean tryLock() {
return sync.tryAcquire(1);
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
return sync.tryAcquireNanos(1, time);
}
@Override
public void unlock() {
sync.release(1);
}
@Override
public Condition newCondition() {
return sync.newCondition();
}
}
class Main {
static int num = 0;
public static void main(String[] args) throws InterruptedException, IOException {
MyLock lock = new MyLock();
Object syncLock = new Object();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
lock.lock();
try {
lock.lock();
try {
lock.lock();
try {
num++;
} finally {
lock.unlock();
}
} finally {
lock.unlock();
}
} finally {
lock.unlock();
}
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
lock.lock();
try {
lock.lock();
try {
lock.lock();
try {
num--;
} finally {
lock.unlock();
}
} finally {
lock.unlock();
}
} finally {
lock.unlock();
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
int x = 0;
}
}13、同步模式之顺序控制
Wait/Notify版本
static final Object LOCK = new Object();
//判断先执行的内容是否执行完毕
static Boolean judge = false;
public static void main(String[] args) {
new Thread(()->{
synchronized (LOCK) {
while (!judge) {
try {
LOCK.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("2");
}
}).start();
new Thread(()->{
synchronized (LOCK) {
System.out.println("1");
judge = true;
//执行完毕,唤醒所有等待线程
LOCK.notifyAll();
}
}).start();
}交替输出
wait/notify版本
public class Test4 {
static Symbol symbol = new Symbol();
public static void main(String[] args) {
new Thread(()->{
symbol.run("a", 1, 2);
}).start();
new Thread(()->{
symbol.run("b", 2, 3);
}).start();
symbol.run("c", 3, 1);
new Thread(()->{
}).start();
}
}
class Symbol {
public synchronized void run(String str, int flag, int nextFlag) {
for(int i=0; i<loopNumber; i++) {
while(flag != this.flag) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(str);
//设置下一个运行的线程标记
this.flag = nextFlag;
//唤醒所有线程
this.notifyAll();
}
}
/**
* 线程的执行标记, 1->a 2->b 3->c
*/
private int flag = 1;
private int loopNumber = 5;
public int getFlag() {
return flag;
}
public void setFlag(int flag) {
this.flag = flag;
}
public int getLoopNumber() {
return loopNumber;
}
public void setLoopNumber(int loopNumber) {
this.loopNumber = loopNumber;
}
}await/signal版本
public class Test5 {
static AwaitSignal awaitSignal = new AwaitSignal();
static Condition conditionA = awaitSignal.newCondition();
static Condition conditionB = awaitSignal.newCondition();
static Condition conditionC = awaitSignal.newCondition();
public static void main(String[] args) {
new Thread(()->{
awaitSignal.run("a", conditionA, conditionB);
}).start();
new Thread(()->{
awaitSignal.run("b", conditionB, conditionC);
}).start();
new Thread(()->{
awaitSignal.run("c", conditionC, conditionA);
}).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
awaitSignal.lock();
try {
//唤醒一个等待的线程
conditionA.signal();
}finally {
awaitSignal.unlock();
}
}
}
class AwaitSignal extends ReentrantLock{
public void run(String str, Condition thisCondition, Condition nextCondition) {
for(int i=0; i<loopNumber; i++) {
lock();
try {
//全部进入等待状态
thisCondition.await();
System.out.print(str);
nextCondition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
unlock();
}
}
}
private int loopNumber=5;
public int getLoopNumber() {
return loopNumber;
}
public void setLoopNumber(int loopNumber) {
this.loopNumber = loopNumber;
}
}14、ThreadLocal
简介
ThreadLocal是JDK包提供的,它提供了线程本地变量,也就是如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地副本。当多个线程操作这个变量时,实际操作的是自己本地内存里面的变量,从而避免了线程安全问题
使用
public class ThreadLocalStudy {
public static void main(String[] args) {
// 创建ThreadLocal变量
ThreadLocal<String> stringThreadLocal = new ThreadLocal<>();
ThreadLocal<User> userThreadLocal = new ThreadLocal<>();
// 创建两个线程,分别使用上面的两个ThreadLocal变量
Thread thread1 = new Thread(()->{
// stringThreadLocal第一次赋值
stringThreadLocal.set("thread1 stringThreadLocal first");
// stringThreadLocal第二次赋值
stringThreadLocal.set("thread1 stringThreadLocal second");
// userThreadLocal赋值
userThreadLocal.set(new User("Nyima", 20));
// 取值
System.out.println(stringThreadLocal.get());
System.out.println(userThreadLocal.get());
// 移除
userThreadLocal.remove();
System.out.println(userThreadLocal.get());
});
Thread thread2 = new Thread(()->{
// stringThreadLocal第一次赋值
stringThreadLocal.set("thread2 stringThreadLocal first");
// stringThreadLocal第二次赋值
stringThreadLocal.set("thread2 stringThreadLocal second");
// userThreadLocal赋值
userThreadLocal.set(new User("Hulu", 20));
// 取值
System.out.println(stringThreadLocal.get());
System.out.println(userThreadLocal.get());
});
// 启动线程
thread1.start();
thread2.start();
}
}
class User {
String name;
int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}运行结果
thread1 stringThreadLocal second
thread2 stringThreadLocal second
User{name='Nyima', age=20}
User{name='Hulu', age=20}
null从运行结果可以看出
- 每个线程中的ThreadLocal变量是每个线程私有的,而不是共享的
- 从线程1和线程2的打印结果可以看出
- ThreadLocal其实就相当于其泛型类型的一个变量,只不过是每个线程私有的
- stringThreadLocal被赋值了两次,保存的是最后一次赋值的结果
- ThreadLocal可以进行以下几个操作
- set 设置值
- get 取出值
- remove 移除值
原理
Thread中的threadLocals
public class Thread implements Runnable {
...
ThreadLocal.ThreadLocalMap threadLocals = null;
// 放在后面说
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
...
}static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}可以看出Thread类中有一个threadLocals和一个inheritableThreadLocals,它们都是ThreadLocalMap类型的变量,而ThreadLocalMap是一个定制化的Hashmap。在默认情况下,每个线程中的这两个变量都为null。此处先讨论threadLocals,inheritableThreadLocals放在后面讨论
ThreadLocal中的方法
set方法
public void set(T value) {
// 获取当前线程
Thread t = Thread.currentThread();
// 获得ThreadLocalMap对象
// 这里的get会返回Thread类中的threadLocals
ThreadLocalMap map = getMap(t);
// 判断map是否已经创建,没创建就创建并放入值,创建了就直接放入
if (map != null)
// ThreadLocal自生的引用作为key,传入的值作为value
map.set(this, value);
else
createMap(t, value);
}如果未创建
void createMap(Thread t, T firstValue) {
// 创建的同时设置想放入的值
// hreadLocal自生的引用作为key,传入的值作为value
t.threadLocals = new ThreadLocalMap(this, firstValue);
}get方法
public T get() {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取当前线程的threadLocals变量
ThreadLocalMap map = getMap(t);
// 判断threadLocals是否被初始化了
if (map != null) {
// 已经初始化则直接返回
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 否则就创建threadLocals
return setInitialValue();
}private T setInitialValue() {
// 这个方法返回是null
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
// 无论map创建与否,最终value的值都为null
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}protected T initialValue() {
return null;
}remove方法
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
// 如果threadLocals已经被初始化,则移除
m.remove(this);
}总结
在每个线程内部都有一个名为threadLocals的成员变量,该变量的类型为HashMap,其中key为我们定义的ThreadLocal变量的this引用,value则为我们使用set方法设置的值。每个线程的本地变量存放在线程自己的内存变量threadLocals中
只有当前线程第一次调用ThreadLocal的set或者get方法时才会创建threadLocals(inheritableThreadLocals也是一样)。其实每个线程的本地变量不是存放在ThreadLocal实例里面,而是存放在调用线程的threadLocals变量里面
15、InheritableThreadLocal
简介
从ThreadLocal的源码可以看出,无论是set、get、还是remove,都是相对于当前线程操作的
Thread.currentThread()所以ThreadLocal无法从父线程传向子线程,所以InheritableThreadLocal出现了,它能够让父线程中ThreadLocal的值传给子线程。
也就是从main所在的线程,传给thread1或thread2
使用
public class Demo1 {
public static void main(String[] args) {
ThreadLocal<String> stringThreadLocal = new ThreadLocal<>();
InheritableThreadLocal<String> stringInheritable = new InheritableThreadLocal<>();
// 主线程赋对上面两个变量进行赋值
stringThreadLocal.set("this is threadLocal");
stringInheritable.set("this is inheritableThreadLocal");
// 创建线程
Thread thread1 = new Thread(()->{
// 获得ThreadLocal中存放的值
System.out.println(stringThreadLocal.get());
// 获得InheritableThreadLocal存放的值
System.out.println(stringInheritable.get());
});
thread1.start();
}
}运行结果
null
this is inheritableThreadLocal可以看出InheritableThreadLocal的值成功从主线程传入了子线程,而ThreadLocal则没有
原理
InheritableThreadLocal
public class InheritableThreadLocal<T> extends ThreadLocal<T> {
// 传入父线程中的一个值,然后直接返回
protected T childValue(T parentValue) {
return parentValue;
}
// 返回传入线程的inheritableThreadLocals
// Thread中有一个inheritableThreadLocals变量
// ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
ThreadLocalMap getMap(Thread t) {
return t.inheritableThreadLocals;
}
// 创建一个inheritableThreadLocals
void createMap(Thread t, T firstValue) {
t.inheritableThreadLocals = new ThreadLocalMap(this, firstValue);
}
}由如上代码可知,InheritableThreadLocal继承了ThreadLocal,并重写了三个方法。InheritableThreadLocal重写了createMap方法,那么现在当第一次调用set方法时,创建的是当前线程的inheritableThreadLocals变量的实例而不再是threadLocals。当调用getMap方法获取当前线程内部的map变量时,获取的是inheritableThreadLocals而不再是threadLocals
childValue(T parentValue)方法的调用
在主函数运行时,会调用Thread的默认构造函数(创建主线程,也就是父线程),所以我们先看看Thread的默认构造函数
public Thread() {
init(null, null, "Thread-" + nextThreadNum(), 0);
}private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
...
// 获得当前线程的,在这里是主线程
Thread parent = currentThread();
...
// 如果父线程的inheritableThreadLocals存在
// 我们在主线程中调用set和get时,会创建inheritableThreadLocals
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
// 设置子线程的inheritableThreadLocals
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
/* Stash the specified stack size in case the VM cares */
this.stackSize = stackSize;
/* Set thread ID */
tid = nextThreadID();
}static ThreadLocalMap createInheritedMap(ThreadLocalMap parentMap) {
return new ThreadLocalMap(parentMap);
}在createInheritedMap内部使用父线程的inheritableThreadLocals变量作为构造函数创建了一个新的ThreadLocalMap变量,然后赋值给了子线程的inheritableThreadLocals变量
private ThreadLocalMap(ThreadLocalMap parentMap) {
Entry[] parentTable = parentMap.table;
int len = parentTable.length;
setThreshold(len);
table = new Entry[len];
for (int j = 0; j < len; j++) {
Entry e = parentTable[j];
if (e != null) {
@SuppressWarnings("unchecked")
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key != null) {
// 这里调用了 childValue 方法
// 该方法会返回parent的值
Object value = key.childValue(e.value);
Entry c = new Entry(key, value);
int h = key.threadLocalHashCode & (len - 1);
while (table[h] != null)
h = nextIndex(h, len);
table[h] = c;
size++;
}
}
}
}在该构造函数内部把父线程的inheritableThreadLocals成员变量的值复制到新的ThreadLocalMap对象中
总结
InheritableThreadLocal类通过重写getMap和createMap,让本地变量保存到了具体线程的inheritableThreadLocals变量里面,那么线程在通过InheritableThreadLocal类实例的set或者get方法设置变量时,就会创建当前线程的inheritableThreadLocals变量。
当父线程创建子线程时,构造函数会把父线程中inheritableThreadLocals变量里面的本地变量复制一份保存到子线程的inheritableThreadLocals变量里面。
四、共享模型之内存
1、JAVA内存模型(JMM)
JMM 即 Java Memory Model,它定义了主存(共享内存)、工作内存(线程私有)抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、 CPU 指令优化等。
JMM体现在以下几个方面
- 原子性 - 保证指令不会受到线程上下文切换的影响
- 可见性 - 保证指令不会受 cpu 缓存的影响
- 有序性 - 保证指令不会受 cpu 指令并行优化的影响
2、可见性
引例
退出不出的循环
static Boolean run = true;
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
while (run) {
//如果run为真,则一直执行
}
}).start();
Thread.sleep(1000);
System.out.println("改变run的值为false");
run = false;
}为什么无法退出该循环
- 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存。
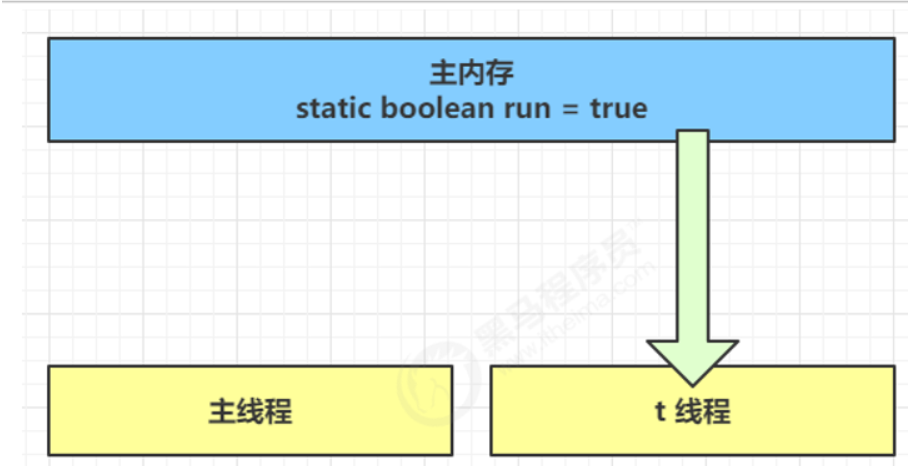
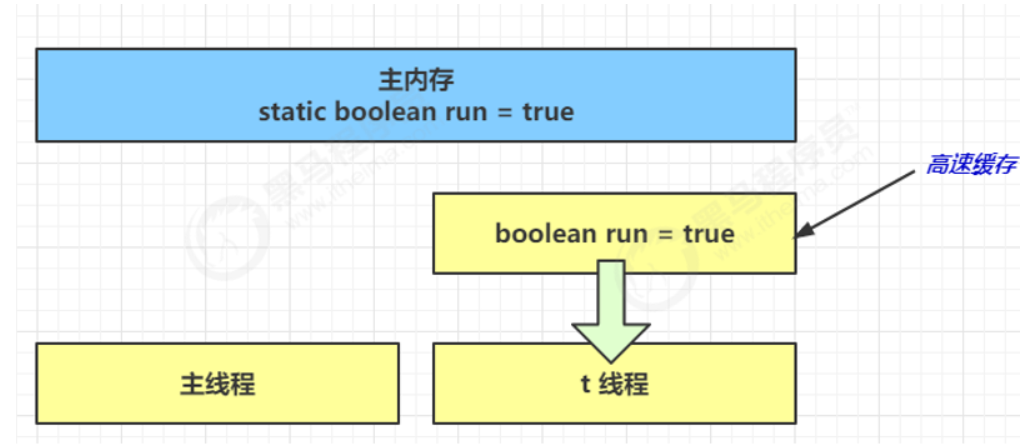
- 因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中, 减少对主存中 run 的访问,提高效率
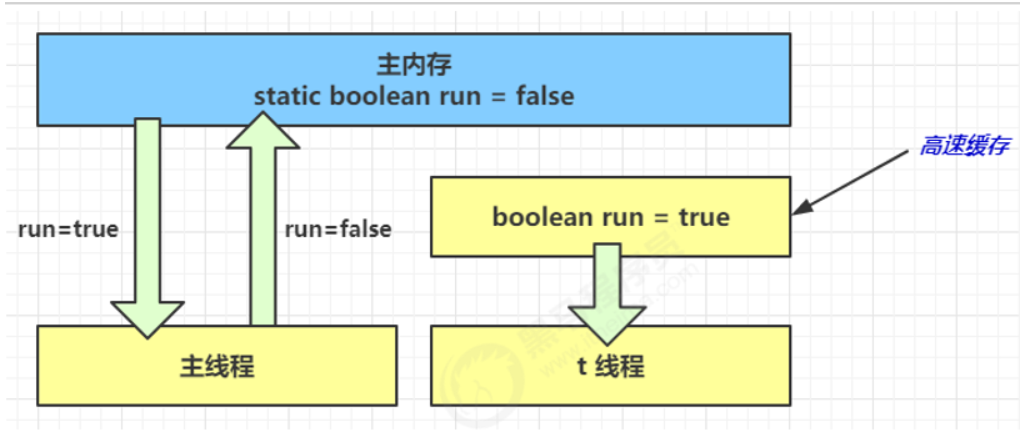
- 1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量 的值,结果永远是旧值
解决方法
- 使用volatile易变关键字
- 它可以用来修饰成员变量和静态成员变量(放在主存中的变量),他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存
//使用易变关键字
volatile static Boolean run = true;
public static void main(String[] args) throws InterruptedException {
new Thread(()->{
while (run) {
//如果run为真,则一直执行
}
}).start();
Thread.sleep(1000);
System.out.println("改变run的值为false");
run = false;
}可见性与原子性
前面例子体现的实际就是可见性,它保证的是在多个线程之间,一个线程对volatile变量的修改对另一个线程可见, 不能保证原子性,仅用在一个写线程,多个读线程的情况
注意 synchronized 语句块既可以保证代码块的原子性,也同时保证代码块内变量的可见性。
但缺点是 synchronized 是属于重量级操作,性能相对更低。
如果在前面示例的死循环中加入 System.out.println() 会发现即使不加 volatile 修饰符,线程 t 也能正确看到 对 run 变量的修改了,想一想为什么?
因为使用了synchronized关键字
public void println(String x) { //使用了synchronized关键字 synchronized (this) { print(x); newLine(); } }
两阶终止模式优化
public class Test7 {
public static void main(String[] args) throws InterruptedException {
Monitor monitor = new Monitor();
monitor.start();
Thread.sleep(3500);
monitor.stop();
}
}
class Monitor {
Thread monitor;
//设置标记,用于判断是否被终止了
private volatile boolean stop = false;
/**
* 启动监控器线程
*/
public void start() {
//设置线控器线程,用于监控线程状态
monitor = new Thread() {
@Override
public void run() {
//开始不停的监控
while (true) {
if(stop) {
System.out.println("处理后续任务");
break;
}
System.out.println("监控器运行中...");
try {
//线程休眠
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.println("被打断了");
}
}
}
};
monitor.start();
}
/**
* 用于停止监控器线程
*/
public void stop() {
//打断线程
monitor.interrupt();
//修改标记
stop = true;
}
}同步模式之犹豫模式
定义
Balking (犹豫)模式用在一个线程发现另一个线程或本线程已经做了某一件相同的事,那么本线程就无需再做 了,直接结束返回
- 用一个标记来判断该任务是否已经被执行过了
- 需要避免线程安全问题
- 加锁的代码块要尽量的小,以保证性能
package com.nyima.day1;
/**
* @author Chen Panwen
* @data 2020/3/26 16:11
*/
public class Test7 {
public static void main(String[] args) throws InterruptedException {
Monitor monitor = new Monitor();
monitor.start();
monitor.start();
Thread.sleep(3500);
monitor.stop();
}
}
class Monitor {
Thread monitor;
//设置标记,用于判断是否被终止了
private volatile boolean stop = false;
//设置标记,用于判断是否已经启动过了
private boolean starting = false;
/**
* 启动监控器线程
*/
public void start() {
//上锁,避免多线程运行时出现线程安全问题
synchronized (this) {
if (starting) {
//已被启动,直接返回
return;
}
//启动监视器,改变标记
starting = true;
}
//设置线控器线程,用于监控线程状态
monitor = new Thread() {
@Override
public void run() {
//开始不停的监控
while (true) {
if(stop) {
System.out.println("处理后续任务");
break;
}
System.out.println("监控器运行中...");
try {
//线程休眠
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.println("被打断了");
}
}
}
};
monitor.start();
}
/**
* 用于停止监控器线程
*/
public void stop() {
//打断线程
monitor.interrupt();
stop = true;
}
}3、有序性
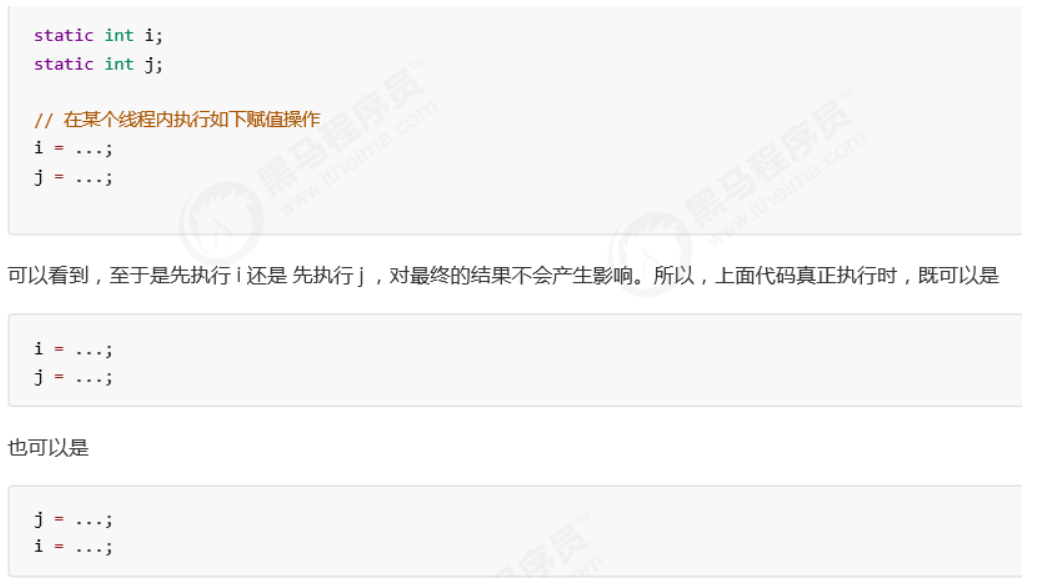
指令重排
- JVM 会在不影响正确性的前提下,可以调整语句的执行顺序
这种特性称之为『指令重排』,多线程下『指令重排』会影响正确性。
指令重排序优化
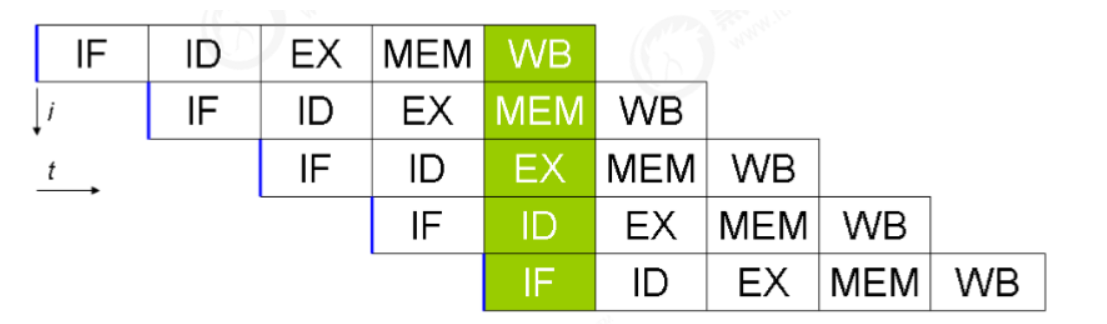
- 事实上,现代处理器会设计为一个时钟周期完成一条执行时间长的 CPU 指令。为什么这么做呢?可以想到指令还可以再划分成一个个更小的阶段,例如,每条指令都可以分为: 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 这5 个阶段

在不改变程序结果的前提下,这些指令的各个阶段可以通过重排序和组合来实现指令级并行
指令重排的前提是,重排指令不能影响结果,例如
// 可以重排的例子 int a = 10; int b = 20; System.out.println( a + b ); // 不能重排的例子 int a = 10; int b = a - 5;
支持流水线的处理器
现代 CPU 支持多级指令流水线,例如支持同时执行 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 的处理器,就可以称之为五级指令流水线。这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(相当于一 条执行时间长的复杂指令),IPC = 1,本质上,流水线技术并不能缩短单条指令的执行时间,但它变相地提高了指令地吞吐率。
在多线程环境下,指令重排序可能导致出现意料之外的结果
解决办法
volatile 修饰的变量,可以禁用指令重排
- 禁止的是加volatile关键字变量之前的代码被重排序
4、内存屏障
- 可见性
- 写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中
- 读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中新数据
- 有序性
- 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
5、volatile 原理
volatile的底层实现原理是内存屏障,Memory Barrier(Memory Fence)
- 对 volatile 变量的写指令后会加入写屏障
- 对 volatile 变量的读指令前会加入读屏障
如何保证可见性
写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中

而读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中新数据
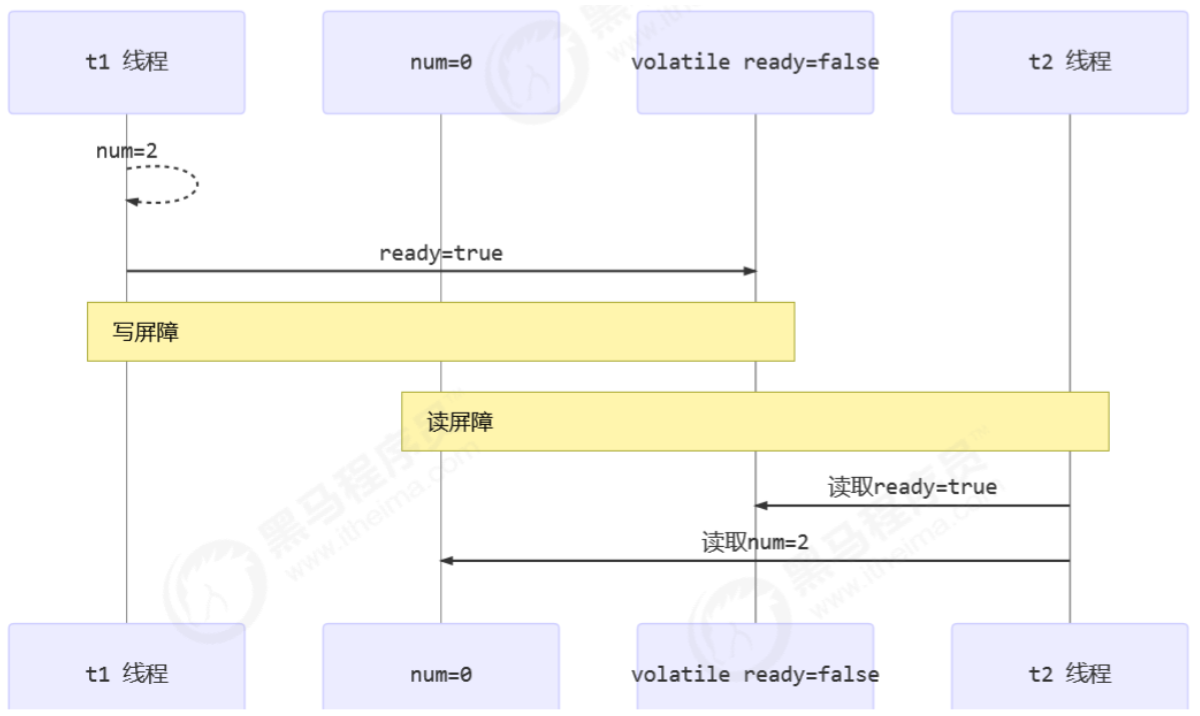
如何保证有序性
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后

读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前

但是不能解决指令交错问题
- 写屏障仅仅是保证之后的读能够读到新的结果,但不能保证读跑到它前面去
- 而有序性的保证也只是保证了本线程内相关代码不被重排序
实现原理之Lock前缀
在X86处理器下通过工具获取JIT编译器生成的汇编指令来查看对volatile进行写操作时
instance = new Singleton();对应的汇编代码是
... lock addl ...有volatile变量修饰的共享变量进行写操作的时候会多出第二行汇编代码,通过查IA-32架构软件开发者手册可知,Lock前缀的指令在多核处理器下会引发了两件事
- Lock前缀指令会引起处理器缓存回写到内存
- Lock前缀指令导致在执行指令期间,声言处理器的LOCK#信号。在多处理器环境中,LOCK#信号确保在声言该信号期间,处理器可以独占任何共享内存。但是,在最近的处理器里,LOCK #信号一般不锁总线,而是锁缓存,毕竟锁总线开销的比较大。使用缓存一致性机制来确保修改的原子性,此操作被称为“缓存锁定”,缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据
- 一个处理器的缓存回写到内存会导致其他处理器的缓存无效
- 在多核处理器系统中进行操作的时候,IA-32和Intel 64处理器能嗅探其他处理器访问系统内存和它们的内部缓存。处理器使用嗅探技术保证它的内部缓存、系统内存和其他处理器的缓存的数据在总线上保持一致
五、共享模型之无锁
1、无锁解决线程安全问题
使用原子整数
AtomicInteger balance = new AtomicInteger();
interface Account {
Integer getBalance();
void withdraw(Integer amount);
/**
* 方法内会启动 1000 个线程,每个线程做 -10 元 的操作 * 如果初始余额为 10000 那么正确的结果应当是 0
*/
static void demo(Account account) {
List<Thread> ts = new ArrayList<>();
long start = System.nanoTime();
for (int i = 0; i < 1000; i++) {
ts.add(new Thread(() -> {
account.withdraw(10);
}));
}
ts.forEach(Thread::start);
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
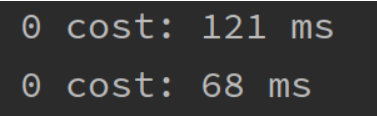
System.out.println(account.getBalance() + " cost: " + (end - start) / 1000_000 + " ms");
}
}
//线程不安全的做法
class AccountUnsafe implements Account {
private Integer balance;
public AccountUnsafe(Integer balance) {
this.balance = balance;
}
@Override
public Integer getBalance() {
return this.balance;
}
@Override
public synchronized void withdraw(Integer amount) {
balance -= amount;
}
public static void main(String[] args) {
Account.demo(new AccountUnsafe(10000));
Account.demo(new AccountCas(10000));
}
}
//线程安全的做法
class AccountCas implements Account {
//使用原子整数
private AtomicInteger balance;
public AccountCas(int balance) {
this.balance = new AtomicInteger(balance);
}
@Override
public Integer getBalance() {
//得到原子整数的值
return balance.get();
}
@Override
public void withdraw(Integer amount) {
while(true) {
//获得修改前的值
int prev = balance.get();
//获得修改后的值
int next = prev-amount;
//比较并设值
if(balance.compareAndSet(prev, next)) {
break;
}
}
}
}2、CAS与volatile
前面看到的 AtomicInteger 的解决方法,内部并没有用锁来保护共享变量的线程安全。那么它是如何实现的呢?
其中的关键是 compareAndSwap(比较并设置值),它的简称就是 CAS (也有 Compare And Swap 的说法),它必须是原子操作。

工作流程
- 当一个线程要去修改Account对象中的值时,先获取值pre(调用get方法),然后再将其设置为新的值next(调用cas方法)。在调用cas方法时,会将pre与Account中的余额进行比较。
- 如果两者相等,就说明该值还未被其他线程修改,此时便可以进行修改操作。
- 如果两者不相等,就不设置值,重新获取值pre(调用get方法),然后再将其设置为新的值next(调用cas方法),直到修改成功为止。
注意
其实 CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核 CPU 和多核 CPU 下都能够保证【比较-交换】的原子性。
在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。
volatile
获取共享变量时,为了保证该变量的可见性,需要使用 volatile 修饰。
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取 它的值,线程操作 volatile 变量都是直接操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
注意
volatile 仅仅保证了共享变量的可见性,让其它线程能够看到新值,但不能解决指令交错问题(不能保证原子性)CAS 必须借助 volatile 才能读取到共享变量的新值来实现【比较并交换】的效果
效率问题
一般情况下,使用无锁比使用加锁的效率更高。
原因
CAS特点
结合 CAS 和 volatile 可以实现无锁并发,适用于线程数少、多核 CPU 的场景下。
- CAS 是基于乐观锁的思想:乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试呗。
- synchronized 是基于悲观锁的思想:悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。
- CAS 体现的是无锁并发、无阻塞并发,请仔细体会这两句话的意思
- 因为没有使用 synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一
- 但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响
3、原子整数
J.U.C 并发包提供了
- AtomicBoolean
- AtomicInteger
- AtomicLong
以 AtomicInteger 为例
AtomicInteger i = new AtomicInteger(0);
// 获取并自增(i = 0, 结果 i = 1, 返回 0),类似于 i++ System.out.println(i.getAndIncrement());
// 自增并获取(i = 1, 结果 i = 2, 返回 2),类似于 ++i System.out.println(i.incrementAndGet());
// 自减并获取(i = 2, 结果 i = 1, 返回 1),类似于 --i System.out.println(i.decrementAndGet());
// 获取并自减(i = 1, 结果 i = 0, 返回 1),类似于 i--
System.out.println(i.getAndDecrement());
// 获取并加值(i = 0, 结果 i = 5, 返回 0)
System.out.println(i.getAndAdd(5));
// 加值并获取(i = 5, 结果 i = 0, 返回 0)
System.out.println(i.addAndGet(-5));
// 获取并更新(i = 0, p 为 i 的当前值, 结果 i = -2, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.getAndUpdate(p -> p - 2));
// 更新并获取(i = -2, p 为 i 的当前值, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.updateAndGet(p -> p + 2));
// 获取并计算(i = 0, p 为 i 的当前值, x 为参数1, 结果 i = 10, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用 // getAndUpdate 如果在 lambda 中引用了外部的局部变量,要保证该局部变量是 final 的
// getAndAccumulate 可以通过 参数1 来引用外部的局部变量,但因为其不在 lambda 中因此不必是
final System.out.println(i.getAndAccumulate(10, (p, x) -> p + x));
// 计算并获取(i = 10, p 为 i 的当前值, x 为参数1, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.accumulateAndGet(-10, (p, x) -> p + x));4、原子引用
public interface DecimalAccount {
BigDecimal getBalance();
void withdraw(BigDecimal amount);
/**
* 方法内会启动 1000 个线程,每个线程做 -10 元 的操作
* 如果初始余额为 10000 那么正确的结果应当是 0
*/
static void demo(DecimalAccountImpl account) {
List<Thread> ts = new ArrayList<>();
long start = System.nanoTime();
for (int i = 0; i < 1000; i++) {
ts.add(new Thread(() -> {
account.withdraw(BigDecimal.TEN);
}));
}
ts.forEach(Thread::start);
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(account.getBalance() + " cost: " + (end - start) / 1000_000 + " ms");
}
}
class DecimalAccountImpl implements DecimalAccount {
//原子引用,泛型类型为小数类型
AtomicReference<BigDecimal> balance;
public DecimalAccountImpl(BigDecimal balance) {
this.balance = new AtomicReference<BigDecimal>(balance);
}
@Override
public BigDecimal getBalance() {
return balance.get();
}
@Override
public void withdraw(BigDecimal amount) {
while(true) {
BigDecimal pre = balance.get();
BigDecimal next = pre.subtract(amount);
if(balance.compareAndSet(pre, next)) {
break;
}
}
}
public static void main(String[] args) {
DecimalAccount.demo(new DecimalAccountImpl(new BigDecimal("10000")));
}
}5、ABA问题
public class Demo3 {
static AtomicReference<String> str = new AtomicReference<>("A");
public static void main(String[] args) {
new Thread(() -> {
String pre = str.get();
System.out.println("change");
try {
other();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//把str中的A改为C
System.out.println("change A->C " + str.compareAndSet(pre, "C"));
}).start();
}
static void other() throws InterruptedException {
new Thread(()-> {
System.out.println("change A->B " + str.compareAndSet("A", "B"));
}).start();
Thread.sleep(500);
new Thread(()-> {
System.out.println("change B->A " + str.compareAndSet("B", "A"));
}).start();
}
}
主线程仅能判断出共享变量的值与初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况,如果主线程希望:
只要有其它线程【动过了】共享变量,那么自己的 cas 就算失败,这时,仅比较值是不够的,需要再加一个版本号
AtomicStampedReference
public class Demo3 {
//指定版本号
static AtomicStampedReference<String> str = new AtomicStampedReference<>("A", 0);
public static void main(String[] args) {
new Thread(() -> {
String pre = str.getReference();
//获得版本号
int stamp = str.getStamp();
System.out.println("change");
try {
other();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//把str中的A改为C,并比对版本号,如果版本号相同,就执行替换,并让版本号+1
System.out.println("change A->C stamp " + stamp + str.compareAndSet(pre, "C", stamp, stamp+1));
}).start();
}
static void other() throws InterruptedException {
new Thread(()-> {
int stamp = str.getStamp();
System.out.println("change A->B stamp " + stamp + str.compareAndSet("A", "B", stamp, stamp+1));
}).start();
Thread.sleep(500);
new Thread(()-> {
int stamp = str.getStamp();
System.out.println("change B->A stamp " + stamp + str.compareAndSet("B", "A", stamp, stamp+1));
}).start();
}
}
AtomicMarkableReference
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如: A -> B -> A -> C ,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。
但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了 AtomicMarkableReference
public class Demo4 {
//指定版本号
static AtomicMarkableReference<String> str = new AtomicMarkableReference<>("A", true);
public static void main(String[] args) {
new Thread(() -> {
String pre = str.getReference();
System.out.println("change");
try {
other();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//把str中的A改为C,并比对版本号,如果版本号相同,就执行替换,并让版本号+1
System.out.println("change A->C mark " + str.compareAndSet(pre, "C", true, false));
}).start();
}
static void other() throws InterruptedException {
new Thread(() -> {
System.out.println("change A->A mark " + str.compareAndSet("A", "A", true, false));
}).start();
}
}
两者的区别
AtomicStampedReference 需要我们传入整型变量作为版本号,来判定是否被更改过
AtomicMarkableReference需要我们传入布尔变量作为标记,来判断是否被更改过
6、原子数组
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
lamba表达式的使用
- 提供者
- 无参又返回
- ()->返回结果
- 方法
- 有参有返回
- (参数一…)->返回结果
- 消费者
- 有参无返回
- (参数一…)->void
7、原子更新器
- AtomicReferenceFieldUpdater // 域 字段
- AtomicIntegerFieldUpdater
- AtomicLongFieldUpdate
原子更新器用于帮助我们改变某个对象中的某个属性
public class Demo1 {
public static void main(String[] args) {
Student student = new Student();
// 获得原子更新器
// 泛型
// 参数1 持有属性的类 参数2 被更新的属性的类
// newUpdater中的参数:第三个为属性的名称
AtomicReferenceFieldUpdater<Student, String> updater = AtomicReferenceFieldUpdater.newUpdater(Student.class, String.class, "name");
// 修改
updater.compareAndSet(student, null, "Nyima");
System.out.println(student);
}
}
class Student {
volatile String name;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
'}';
}
}原子更新器初始化过程
从上面的例子可以看出,原子更新器是通过newUpdater来获取实例的。其中传入了三个参数
- 拥有属性的类的Class
- 属性的Class
- 属性的名称
大概可以猜出来,初始化过程用到了反射,让我们看看源码来验证一下这个猜测。
newUpdater方法
public static <U,W> AtomicReferenceFieldUpdater<U,W> newUpdater(Class<U> tclass,
Class<W> vclass,
String fieldName) {
// 返回了一个AtomicReferenceFieldUpdaterImpl实例
return new AtomicReferenceFieldUpdaterImpl<U,W>
(tclass, vclass, fieldName, Reflection.getCallerClass());
}从newUpdater方法还并不能看出来具体的初始化过程
内部实现类
AtomicReferenceFieldUpdater为抽象类,该类内部有一个自己的实现类AtomicReferenceFieldUpdaterImpl
private static final class AtomicReferenceFieldUpdaterImpl<T,V>
extends AtomicReferenceFieldUpdater<T,V>
构造方法
AtomicReferenceFieldUpdaterImpl(final Class<T> tclass,
final Class<V> vclass,
final String fieldName,
final Class<?> caller) {
// 用于保存要被修改的属性
final Field field;
// 属性的Class
final Class<?> fieldClass;
// field的修饰符
final int modifiers;
try {
// 反射获得属性
field = AccessController.doPrivileged(
new PrivilegedExceptionAction<Field>() {
public Field run() throws NoSuchFieldException {
// tclass为传入的属性的Class,可以通过它来获得属性
return tclass.getDeclaredField(fieldName);
}
});
// 获得属性的修饰符,主要用于判断
// 1、vclass 与 属性确切的类型是否匹配
// 2、是否为引用类型
// 3、被修改的属性是否加了volatile关键字
modifiers = field.getModifiers();
sun.reflect.misc.ReflectUtil.ensureMemberAccess(
caller, tclass, null, modifiers);
ClassLoader cl = tclass.getClassLoader();
ClassLoader ccl = caller.getClassLoader();
if ((ccl != null) && (ccl != cl) &&
((cl == null) || !isAncestor(cl, ccl))) {
sun.reflect.misc.ReflectUtil.checkPackageAccess(tclass);
}
// 获得属性类的Class
fieldClass = field.getType();
} catch (PrivilegedActionException pae) {
throw new RuntimeException(pae.getException());
} catch (Exception ex) {
throw new RuntimeException(ex);
}
if (vclass != fieldClass)
throw new ClassCastException();
if (vclass.isPrimitive())
throw new IllegalArgumentException("Must be reference type");
if (!Modifier.isVolatile(modifiers))
throw new IllegalArgumentException("Must be volatile type");
// Access to protected field members is restricted to receivers only
// of the accessing class, or one of its subclasses, and the
// accessing class must in turn be a subclass (or package sibling)
// of the protected member's defining class.
// If the updater refers to a protected field of a declaring class
// outside the current package, the receiver argument will be
// narrowed to the type of the accessing class.
// 对类中的属性进行初始化
this.cclass = (Modifier.isProtected(modifiers) &&
tclass.isAssignableFrom(caller) &&
!isSamePackage(tclass, caller))
? caller : tclass;
this.tclass = tclass;
this.vclass = vclass;
// 获得偏移量
this.offset = U.objectFieldOffset(field);
}可以看出,原子引用更新器确实使用了反射
8、LongAdder原理
原理之伪共享
缓存行伪共享得从缓存说起
缓存与内存的速度比较
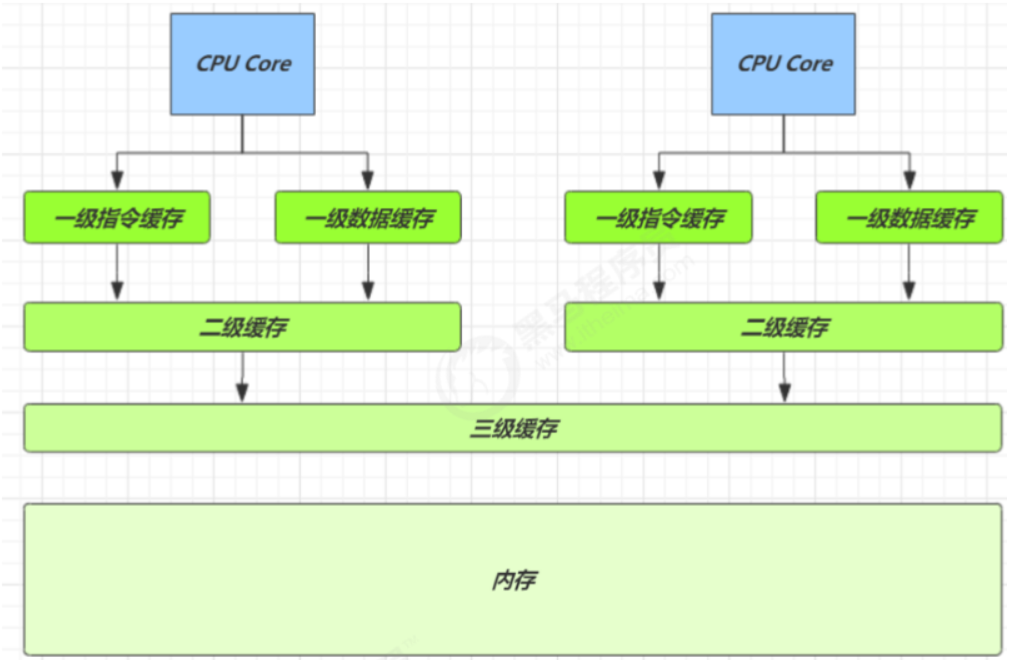
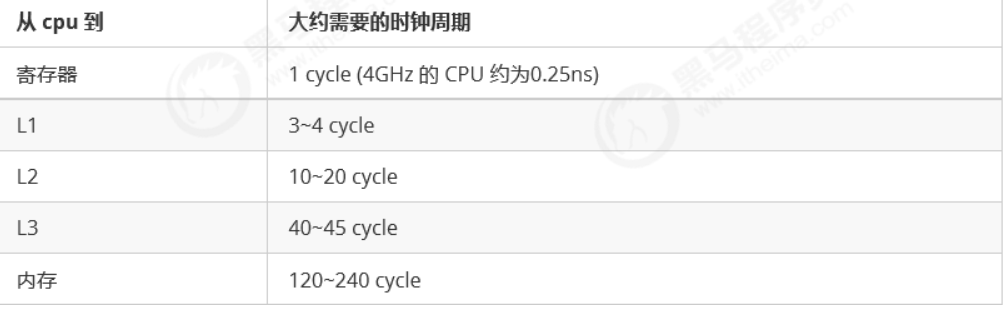
因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。
而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long)
缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中
CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效
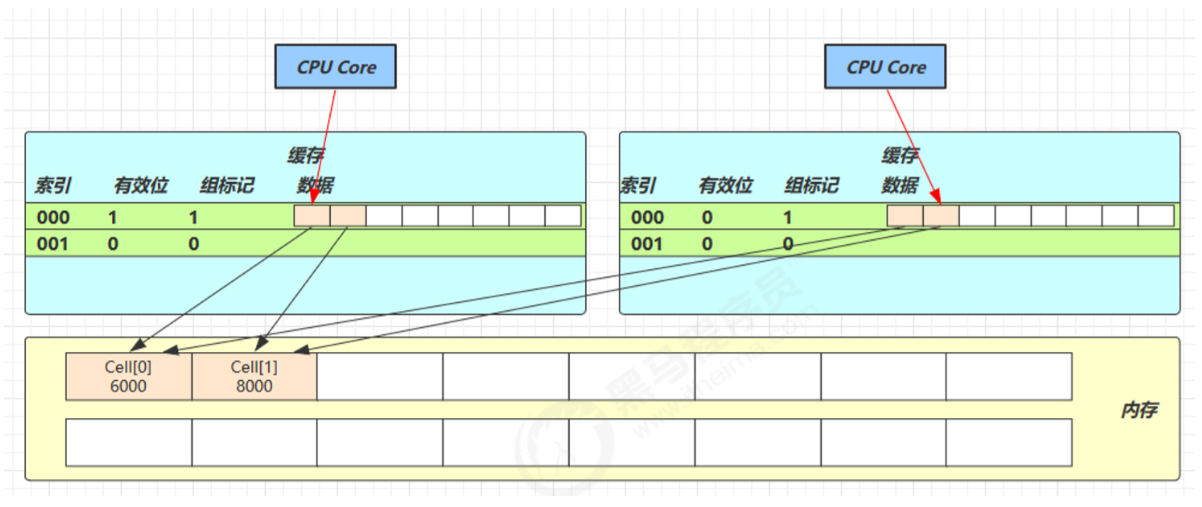
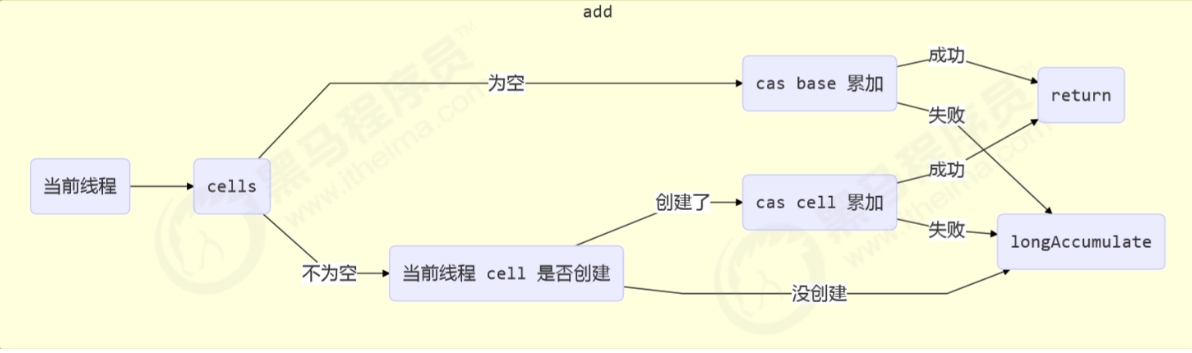
因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因 此缓存行可以存下 2 个的 Cell 对象。这样问题来了:
- Core-0 要修改 Cell[0]
- Core-1 要修改 Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效,
比如 Core-0 中 Cell[0]=6000, Cell[1]=8000 要累加 Cell[0]=6001, Cell[1]=8000 ,这时会让 Core-1 的缓存行失效
@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的 padding(空白),从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效
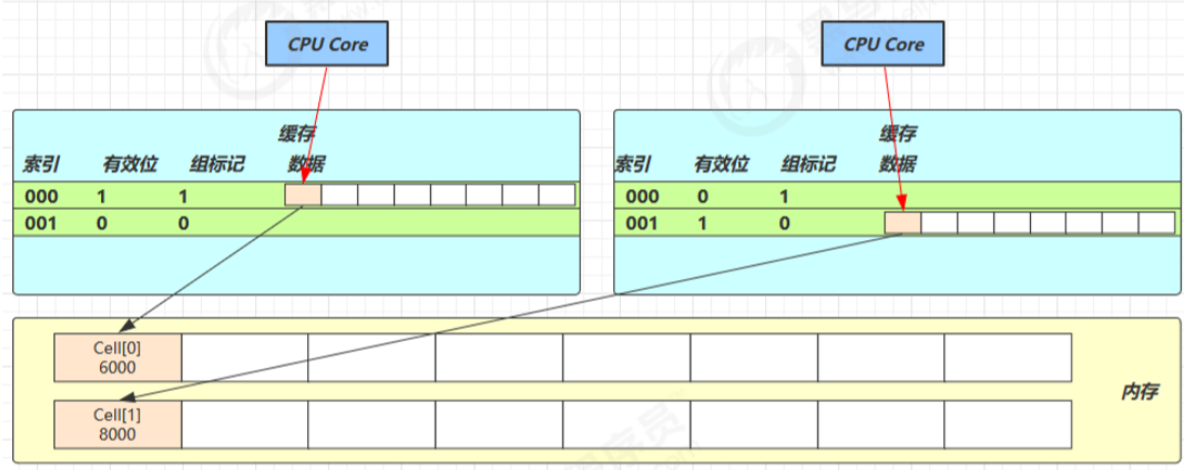
累加主要调用以下方法
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}累加流程图
9、Unsafe
Unsafe 对象提供了非常底层的,操作内存、线程的方法,Unsafe 对象不能直接调用,只能通过反射获得
public class GetUnsafe {
public static void main(String[] args) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException, NoSuchFieldException {
// 通过反射获得Unsafe对象
Class unsafeClass = Unsafe.class;
// 获得构造函数,Unsafe的构造函数为私有的
Constructor constructor = unsafeClass.getDeclaredConstructor();
// 设置为允许访问私有内容
constructor.setAccessible(true);
// 创建Unsafe对象
Unsafe unsafe = (Unsafe) constructor.newInstance();
// 创建Person对象
Person person = new Person();
// 获得其属性 name 的偏移量
Field field = Person.class.getDeclaredField("name");
long offset = unsafe.objectFieldOffset(field);
// 通过unsafe的CAS操作改变值
unsafe.compareAndSwapObject(person, offset, null, "Nyima");
System.out.println(person);
}
}
class Person {
// 配合CAS操作,必须用volatile修饰
volatile String name;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
'}';
}
}六、共享模型之不可变
1、不可变
如果一个对象在不能够修改其内部状态(属性),那么它就是线程安全的,因为不存在并发修改。
2、不可变设计
String类中不可变的体现
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
//....
}
}final 的使用 **
发现该类、类中所有属性都是 **final 的
- 属性用 final 修饰保证了该属性是只读的,不能修改
- 类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
*保护性拷贝 *
但有同学会说,使用字符串时,也有一些跟修改相关的方法啊,比如 substring 等,那么下面就看一看这些方法是 如何实现的,就以 substring 为例
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
//返回的是一个新的对象
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}发现其内部是调用 String 的构造方法创建了一个新字符串
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}构造新字符串对象时,会生成新的 char[] value,对内容进行复制 。这种通过创建副本对象来避免共享的手段称之为【保护性拷贝(defensive copy)】
七、线程池
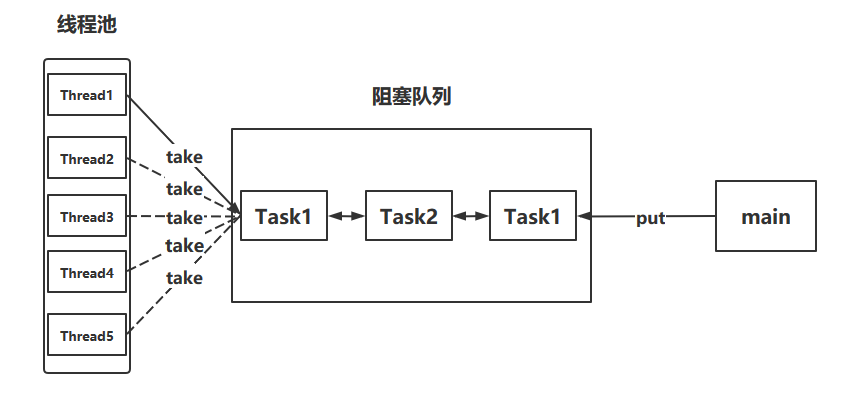
1、自定义线程池
图解
- 阻塞队列中维护了由主线程(或者其他线程)所产生的的任务
- 主线程类似于生产者,产生任务并放入阻塞队列中
- 线程池类似于消费者,得到阻塞队列中已有的任务并执行
代码
public class Demo3 {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(2, TimeUnit.SECONDS, 1, 4);
for (int i = 0; i < 10; i++) {
threadPool.execute(()->{
try {
TimeUnit.SECONDS.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务正在执行!");
});
}
}
}
/**
* 自定义线程池
*/
class ThreadPool {
/**
* 自定义阻塞队列
*/
private BlockingQueue<Runnable> blockingQueue;
/**
* 核心线程数
*/
private int coreSize;
private HashSet<Worker> workers = new HashSet<>();
/**
* 用于指定线程最大存活时间
*/
private TimeUnit timeUnit;
private long timeout;
/**
* 工作线程类
* 内部封装了Thread类,并且添加了一些属性
*/
private class Worker extends Thread {
Runnable task;
public Worker(Runnable task) {
System.out.println("初始化任务");
this.task = task;
}
@Override
public void run() {
// 如果有任务就执行
// 如果阻塞队列中有任务,就继续执行
while (task != null || (task = blockingQueue.take()) != null) {
try {
System.out.println("执行任务");
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 任务执行完毕,设为空
System.out.println("任务执行完毕");
task = null;
}
}
// 移除任务
synchronized (workers) {
System.out.println("移除任务");
workers.remove(this);
}
}
}
public ThreadPool(int coreSize, TimeUnit timeUnit, long timeout, int capacity) {
this.coreSize = coreSize;
this.timeUnit = timeUnit;
blockingQueue = new BlockingQueue<>(capacity);
this.timeout = timeout;
}
public void execute(Runnable task) {
synchronized (workers) {
// 创建任务
// 池中还有空余线程时,可以运行任务
// 否则阻塞
if (workers.size() < coreSize) {
Worker worker = new Worker(task);
workers.add(worker);
worker.start();
} else {
System.out.println("线程池中线程已用完,请稍等");
blockingQueue.put(task);
}
}
}
}
/**
* 阻塞队列
* 用于存放主线程或其他线程产生的任务
*/
class BlockingQueue<T> {
/**
* 阻塞队列
*/
private Deque<T> blockingQueue;
/**
* 阻塞队列容量
*/
private int capacity;
/**
* 锁
*/
private ReentrantLock lock;
/**
* 条件队列
*/
private Condition fullQueue;
private Condition emptyQueue;
public BlockingQueue(int capacity) {
blockingQueue = new ArrayDeque<>(capacity);
lock = new ReentrantLock();
fullQueue = lock.newCondition();
emptyQueue = lock.newCondition();
this.capacity = capacity;
}
/**
* 获取任务的方法
*/
public T take() {
// 加锁
lock.lock();
try {
// 如果阻塞队列为空(没有任务),就一直等待
while (blockingQueue.isEmpty()) {
try {
emptyQueue.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 获取任务并唤醒生产者线程
T task = blockingQueue.removeFirst();
fullQueue.signalAll();
return task;
} finally {
lock.unlock();
}
}
public T takeNanos(long timeout, TimeUnit unit) {
// 转换等待时间
lock.lock();
try {
long nanos = unit.toNanos(timeout);
while (blockingQueue.isEmpty()) {
try {
// awaitNanos会返回剩下的等待时间
nanos = emptyQueue.awaitNanos(nanos);
if (nanos < 0) {
return null;
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T task = blockingQueue.removeFirst();
fullQueue.signalAll();
return task;
} finally {
lock.unlock();
}
}
/**
* 放入任务的方法
* @param task 放入阻塞队列的任务
*/
public void put(T task) {
lock.lock();
try {
while (blockingQueue.size() == capacity) {
try {
System.out.println("阻塞队列已满");
fullQueue.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
blockingQueue.add(task);
// 唤醒等待的消费者
emptyQueue.signalAll();
} finally {
lock.unlock();
}
}
public int getSize() {
lock.lock();
try {
return blockingQueue.size();
} finally {
lock.unlock();
}
}
}实现了一个简单的线程池
- 阻塞队列BlockingQueue用于暂存来不及被线程执行的任务
- 也可以说是平衡生产者和消费者执行速度上的差异
- 里面的获取任务和放入任务用到了生产者消费者模式
- 线程池中对线程Thread进行了再次的封装,封装为了Worker
- 在调用任务的run方法时,线程会去执行该任务,执行完毕后还会到阻塞队列中获取新任务来执行
- 线程池中执行任务的主要方法为execute方法
- 执行时要判断正在执行的线程数是否大于了线程池容量
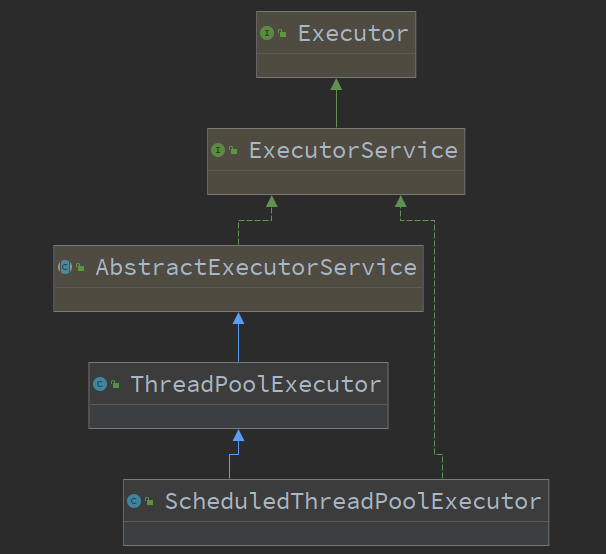
2、ThreadPoolExecutor
继承关系
线程池状态
// 线程池状态
// runState is stored in the high-order bits
// RUNNING 高3位为111
private static final int RUNNING = -1 << COUNT_BITS;
// SHUTDOWN 高3位为000
private static final int SHUTDOWN = 0 << COUNT_BITS;
// 高3位 001
private static final int STOP = 1 << COUNT_BITS;
// 高3位 010
private static final int TIDYING = 2 << COUNT_BITS;
// 高3位 011
private static final int TERMINATED = 3 << COUNT_BITS;| 状态名称 | 高3位的值 | 描述 |
|---|---|---|
| RUNNING | 111 | 接收新任务,同时处理任务队列中的任务 |
| SHUTDOWN | 000 | 不接受新任务,但是处理任务队列中的任务 |
| STOP | 001 | 中断正在执行的任务,同时抛弃阻塞队列中的任务 |
| TIDYING | 010 | 任务执行完毕,活动线程为0时,即将进入终结阶段 |
| TERMINATED | 011 | 终结状态 |
线程池状态和线程池中线程的数量由一个原子整型ctl来共同表示
- 使用一个数来表示两个值的主要原因是:可以通过一次CAS同时更改两个属性的值
// 原子整数,前3位保存了线程池的状态,剩余位保存的是线程数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 并不是所有平台的int都是32位。
// 去掉前三位保存线程状态的位数,剩下的用于保存线程数量
// 高3位为0,剩余位数全为1
private static final int COUNT_BITS = Integer.SIZE - 3;
// 2^COUNT_BITS次方,表示可以保存的最大线程数
// CAPACITY 的高3位为 0
private static final int CAPACITY = (1 << COUNT_BITS) - 1;获取线程池状态、线程数量以及合并两个值的操作
// Packing and unpacking ctl
// 获取运行状态
// 该操作会让除高3位以外的数全部变为0
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 获取运行线程数
// 该操作会让高3位为0
private static int workerCountOf(int c) { return c & CAPACITY; }
// 计算ctl新值
private static int ctlOf(int rs, int wc) { return rs | wc; }线程池属性
// 工作线程,内部封装了Thread
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable {
...
}
// 阻塞队列,用于存放来不及被核心线程执行的任务
private final BlockingQueue<Runnable> workQueue;
// 锁
private final ReentrantLock mainLock = new ReentrantLock();
// 用于存放核心线程的容器,只有当持有锁时才能够获取其中的元素(核心线程)
private final HashSet<Worker> workers = new HashSet<Worker>();构造方法极其参数
ThreadPoolExecutor最全面的构造方法
也是构造自定义线程池的方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)参数解释
- corePoolSize:核心线程数
- maximumPoolSize:最大线程数
- maximumPoolSize - corePoolSize = 救急线程数
- keepAliveTime:救急线程空闲时的最大生存时间
- unit:时间单位
- workQueue:阻塞队列(存放任务)
- 有界阻塞队列 ArrayBlockingQueue
- 无界阻塞队列 LinkedBlockingQueue
- 最多只有一个同步元素的 SynchronousQueue
- 优先队列 PriorityBlockingQueue
- threadFactory:线程工厂(给线程取名字)
- handler:拒绝策略
工作方式
- 当一个任务传给线程池以后,可能有以下几种可能
- 将任务分配给一个核心线程来执行
- 核心线程都在执行任务,将任务放到阻塞队列workQueue中等待被执行
- 阻塞队列满了,使用救急线程来执行任务
- 救急线程用完以后,超过生存时间(keepAliveTime)后会被释放
- 任务总数大于了 最大线程数(maximumPoolSize)与阻塞队列容量的最大值(workQueue.capacity),使用拒接策略
拒绝策略
如果线程到达 maximumPoolSize 仍然有新任务这时会执行拒绝策略。拒绝策略 jdk 提供了 4 种实现

- AbortPolicy:让调用者抛出 RejectedExecutionException 异常,这是默认策略
- CallerRunsPolicy:让调用者运行任务
- DiscardPolicy:放弃本次任务
- DiscardOldestPolicy:放弃队列中最早的任务,本任务取而代之
使用
public class Demo1 {
static AtomicInteger threadId = new AtomicInteger(0);
public static void main(String[] args) {
// 手动创建线程池
// 创建有界阻塞队列
ArrayBlockingQueue<Runnable> runnable = new ArrayBlockingQueue<Runnable>(10);
// 创建线程工厂
ThreadFactory threadFactory = new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r, "working_thread_"+threadId.getAndIncrement());
return thread;
}
};
// 手动创建线程池
// 拒绝策略采用默认策略
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 7, 10, TimeUnit.SECONDS, runnable, threadFactory);
for (int i = 0; i < 20; i++) {
executor.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread());
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}FixedThreadPool
public class TestFixedThreadPool {
public static void main(String[] args) {
// 自定义线程工厂
ThreadFactory factory = new ThreadFactory() {
AtomicInteger atomicInteger = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "myThread_" + atomicInteger.getAndIncrement());
}
};
// 创建核心线程数量为2的线程池
// 通过 ThreadFactory可以给线程添加名字
ExecutorService executorService = Executors.newFixedThreadPool(2, factory);
// 任务
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
System.out.println("this is fixedThreadPool");
}
};
executorService.execute(runnable);
}
}固定大小的线程池可以传入两个参数
- 核心线程数:nThreads
- 线程工厂:threadFactory
内部调用的构造方法
ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);CachedThreadPool
ExecutorService executorService = Executors.newCachedThreadPool();内部构造方法
ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());没有核心线程,最大线程数为Integer.MAX_VALUE,所有创建的线程都是救急线程,空闲时生存时间为60秒
阻塞队列使用的是SynchronousQueue
- SynchronousQueue是一种特殊的队列
- 没有容量,没有线程来取是放不进去的
- 只有当线程取任务时,才会将任务放入该阻塞队列中
- SynchronousQueue是一种特殊的队列
SingleThread
ExecutorService service = Executors.newSingleThreadExecutor();内部构造方法
new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));内部调用了new ThreadPoolExecutor的构造方法,传入的corePoolSize和maximumPoolSize都为1。然后将该对象传给了FinalizableDelegatedExecutorService。该类修饰了ThreadPoolExecutor,让外部无法调用ThreadPoolExecutor内部的某些方法来修改所创建的线程池的大小。
几个注意
SingleThread和自己创建一个线程来运行多个任务的区别
- 当线程正在执行的任务发生错误时,如果是自己创建的线程,该任务和剩余的任务就无法再继续运行下去。而SingleThread会创建一个新线程,继续执行任务队列中剩余的任务。
SingleThread和newFixedThreadPool(1)的区别
- newFixedThreadPool(1)传值为1,可以将FixedThreadPool强转为ThreadPoolExecutor,然后通过setCorePoolSize改变核心线程数
// 强转为ThreadPoolExecutor ThreadPoolExecutor threadPool = (ThreadPoolExecutor) Executors.newFixedThreadPool(1); // 改变核心线程数 threadPool.setCorePoolSize(2);- 而SingleThread无法修改核心线程数
执行任务
execute()方法
execute(Runnable command)传入一个Runnable对象,执行其中的run方法
源码解析
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// 获取ctl
int c = ctl.get();
// 判断当前启用的线程数是否小于核心线程数
if (workerCountOf(c) < corePoolSize) {
// 为该任务分配线程
if (addWorker(command, true))
// 分配成功就返回
return;
// 分配失败再次获取ctl
c = ctl.get();
}
// 分配和信息线程失败以后
// 如果池状态为RUNNING并且插入到任务队列成功
if (isRunning(c) && workQueue.offer(command)) {
// 双重检测,可能在添加后线程池状态变为了非RUNNING
int recheck = ctl.get();
// 如果池状态为非RUNNING,则不会执行新来的任务
// 将该任务从阻塞队列中移除
if (! isRunning(recheck) && remove(command))
// 调用拒绝策略,拒绝该任务的执行
reject(command);
// 如果没有正在运行的线程
else if (workerCountOf(recheck) == 0)
// 就创建新线程来执行该任务
addWorker(null, false);
}
// 如果添加失败了(任务队列已满),就调用拒绝策略
else if (!addWorker(command, false))
reject(command);
}其中调用了addWoker()方法,再看看看这个方法
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
// 如果池状态为非RUNNING状态、线程池为SHUTDOWN且该任务为空 或者阻塞队列中已经有任务
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
// 创建新线程失败
return false;
for (;;) {
// 获得当前工作线程数
int wc = workerCountOf(c);
// 参数中 core 为true
// CAPACITY 为 1 << COUNT_BITS-1,一般不会超过
// 如果工作线程数大于了核心线程数,则创建失败
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 通过CAS操作改变c的值
if (compareAndIncrementWorkerCount(c))
// 更改成功就跳出多重循环,且不再运行循环
break retry;
// 更改失败,重新获取ctl的值
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
// 跳出多重循环,且重新进入循环
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// 用于标记work中的任务是否成功执行
boolean workerStarted = false;
// 用于标记worker是否成功加入了线程池中
boolean workerAdded = false;
Worker w = null;
try {
// 创建新线程来执行任务
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
// 加锁
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
// 加锁的同时再次检测
// 避免在释放锁之前调用了shut down
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// 将线程添加到线程池中
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
// 添加成功标志位变为true
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 如果worker成功加入了线程池,就执行其中的任务
if (workerAdded) {
t.start();
// 启动成功
workerStarted = true;
}
}
} finally {
// 如果执行失败
if (! workerStarted)
// 调用添加失败的函数
addWorkerFailed(w);
}
return workerStarted;
}submit()方法
Future<T> submit(Callable<T> task)传入一个Callable对象,用Future来捕获返回值
使用
// 通过submit执行Callable中的call方法
// 通过Future来捕获返回值
Future<String> future = threadPool.submit(new Callable<String>() {
@Override
public String call() throws Exception {
return "hello submit";
}
});
// 查看捕获的返回值
System.out.println(future.get());停止
shutdown()
/**
* 将线程池的状态改为 SHUTDOWN
* 不再接受新任务,但是会将阻塞队列中的任务执行完
*/
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改线程池状态为 SHUTDOWN
advanceRunState(SHUTDOWN);
// 中断空闲线程(没有执行任务的线程)
// Idle:空闲的
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
// 尝试终结,不一定成功
//
tryTerminate();
}final void tryTerminate() {
for (;;) {
int c = ctl.get();
// 终结失败的条件
// 线程池状态为RUNNING
// 线程池状态为 RUNNING SHUTDOWN STOP (状态值大于TIDYING)
// 线程池状态为SHUTDOWN,但阻塞队列中还有任务等待执行
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
// 如果活跃线程数不为0
if (workerCountOf(c) != 0) { // Eligible to terminate
// 中断空闲线程
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 处于可以终结的状态
// 通过CAS将线程池状态改为TIDYING
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
terminated();
} finally {
// 通过CAS将线程池状态改为TERMINATED
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}shutdownNow()
/**
* 将线程池的状态改为 STOP
* 不再接受新任务,也不会在执行阻塞队列中的任务
* 会将阻塞队列中未执行的任务返回给调用者
*/
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改状态为STOP,不执行任何任务
advanceRunState(STOP);
// 中断所有线程
interruptWorkers();
// 将未执行的任务从队列中移除,然后返回给调用者
tasks = drainQueue();
} finally {
mainLock.unlock();
}
// 尝试终结,一定会成功,因为阻塞队列为空了
tryTerminate();
return tasks;
}本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!